Data Structure
开学第一课
前言
CS61B 毫无疑问是一门经典好课,但这篇博客是依托又臭又长的构式。它仅作为本人学习时用于备忘的笔记,分类极其混乱,也没有任何勘误,不建议任何人作为学习上的参考。
但如果有人仍坚持要看的话,由于篇幅原因,这篇文章大概只会介绍课程中的 Java 基础,具体的数据结构内容请点击链接跳转。
当然也非常欢迎品鉴了这坨的大佬们在评论区批评指正。
我们的第一个 Java 程序
Hello World
- 在 Java 中,所有代码必须是类的一部分;
- 类使用
public class CLASSNAME来定义; - 使用大括号{}描述开始与结束;
- 使用分号作为一行的结尾;
- 我们想要运行的代码必须在
public static void main(String[] args)中。
public class HelloWorld { |
Hello Numbers
- Java 变量在使用前必须先声明;
- Java 变量必须有特定类型;
- Java 变量的类型永远无法改变;
- 在代码运行前,类型会先被验证。
public class HelloNumbers { |
Larger
- Java 中,函数必须被作为类的一部分声明。函数作为类的一部分被称作“方法”,所以 Java 中,所有的函数都是方法;
- Java 中我们使用
public static定义函数,更多方式将在后面见到; - 函数的所有参数必须被声明类型,函数的返回值也必须被声明类型。Java 中的函数只能返回一个值!
public class LargerDemo { |
补充一下:
在 Java 中,编译和解释是两个独立的步骤。
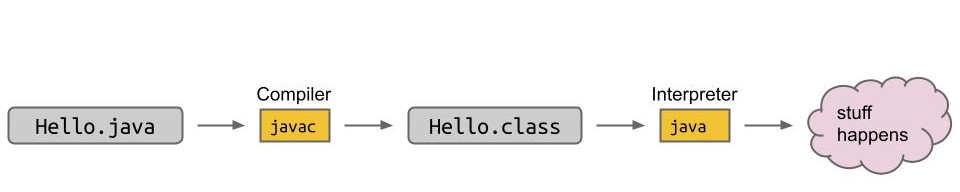
.class 文件可以轻松反编译为高度相似的 Java 源代码。
Statically Typed Language(静态类型语言)是一种编程语言的类型系统特性,指在编译阶段(而非运行时)就确定变量、方法参数和返回值的类型,并在编译时进行类型检查。Java 是一种静态类型语言。
Object-Oriented Programming
学一门语言永远逃不掉的面向对象
- 一种组织程序的模型
- 模块化:可以单独实现程序的一部分而不需要担心其他部分。
- 数据抽象:不需要知道对象内部的具体实现也可以调用该对象。
就像蓝桥杯上不会写排序,也可以直接调用.sort()
- 类与对象
- 类是对象的模板,对象是类的具体实现。
就像小狗有很多品种,但它们都是狗
- 类是对象的模板,对象是类的具体实现。
public class Car { |
Java 中的类
类的定义与实例化
如上一节所说:
- 所有代码必须在一个类中;
- 为了运行一个类,我们必须定义一个主方法。
- 并非所有类都有一个主方法!
狗狗们都是怎么叫的?或许我们可以用一个类统一地表述:
public class Dog { |
然而,并非所有狗都是“barkbark”地叫。但若是为每种叫法都创建一个类,未免显得有些愚笨······我们能不能利用这个类做点事情?
通常地,一只狗发出的声音取决于它的重量,于是:
public class Dog { |
静态成员 vs. 实例成员
看到这之前,你也许会想:他妈的,老是讲“实例”“静态”的,到底啥意思?我也是这么想的。
当我们的变量或方法是静态(static)的时候,这个变量或方法是通用的,适用于所有狗而不是任何特定的狗,比如:狗都是如何发出声音的?而非静态的(non-static,又名实例,instance)变量或方法是针对一个特定狗的,比如:小狗Maya是如何发出声音的?
- 静态方法(变量)使用类名调用,如:
Dog.makeNoise(); - 实例方法(变量)使用实例名(对象)调用,如:
maya.makeNoise(); - 静态方法无法访问实例变量,也无法调用实例方法,但反过来是可以的。
- 静态方法只与类有关,与实例化的对象无关。静态方法甚至不需要创建对象就可以直接调用,如:
x = Math.round(5,6);要比
- 静态方法只与类有关,与实例化的对象无关。静态方法甚至不需要创建对象就可以直接调用,如:
Math m = new Math(); |
方便太多了。
- 如果传递一个对象的引用到静态方法,这样可以访问和调用该对象的实例变量与实例方法,如:
public static Dog maxDog(Dog d1, Dog d2) { |
- 应当始终通过类名访问静态变量,而非实例名。强烈建议避免使用值可变的静态变量。
Java 中的类型
为了引入这节的内容,我们将从一个海象谜团开始:
// 我们现在有一个海象类: |

左侧程序中,对海象 b 的修改会影响海象 a 的体重吗?右侧程序中,对 x 的修改又会影响 y 的值吗?
考虑好答案了吗?
在揭晓答案之前,我们不得不介绍一些你在计算机科学职业生涯中可能会一直使用的东西。
基本类型(Primitive Types)
Bits
深入电脑的最底层,你将发现一堆“0”和“1”
- 我们看到的数据必须被编码为一系列的“0”和“1”以便存储在内存中,例如:
- 72 被存储为 01001000;
- 205.75 被存储为 0 10000110 10011011100000000000000;
- 字母
H被存储为 01001000(与数字72相同); True被存储为 00000001。
- 在 Java 中每个变量都有关联的类型,每种类型都有不同的方式来解释这些二进制位
- Java 中的8种基本类型(Primitive Types):
byte、short、int、long、float、double、boolean、char - 在 61C 中会解释更多细节
- Java 中的8种基本类型(Primitive Types):
声明变量
在 Java 中声明特定类型的变量时:
- 你的计算机会分配刚好足够的二进制位来存储该类型的值,例如:
- 声明一个
int会分配一个 32 位的“盒子”; - 声明一个
double会分配一个 64 位的“盒子”。
- 声明一个
- Java 会创建一个内部映射表,将每个变量名关联到一个内存位置;
- Java 不会在这些预留的盒子中写入任何内容。
- 出于安全考虑,Java 不允许你访问未初始化的变量!
等号的黄金法则(The Golden Rule of Equals)
等号的黄金法则:
“赋值操作(=)将右侧的值(或表达式结果)写入左侧的变量所代表的内存位置。”
也就是说如果你有一个 y = x 语句,等号所做的一切就是将 x 的值复制出一份副本放在 y 中,最终我们会得到:

所以 x = 2; 只会对 x 对应内存位置的内容进行修改,并不会影响 y 中的副本。
引用类型(Reference Types)
看来我们得到了第二个问题的答案,但为了解开海象谜团,我们还不得不搞清楚 Walrus a = new Walrus(1000, 10.8); 究竟做了什么事。
很明显,上面提到的 8 种基本类型并不包括我们的 Walrus。除了基本类型,其他任何类型都是引用类型。
类的实例化(等号右边)
当我们实例化一个对象时,实际上是创建了对该对象的引用。
什么意思呢?对于 new Walrus(1000, 8.3);:
- Java 首先会遍历整个内存,找到一块合适的位置为类的每个实例变量分配一个二进制的盒子,并用默认值填充(例如 0、false 或 null);
- 构造器随后会将这些存储盒中的值替换为指定的初始值;
- 就像埋下了个宝藏,我们得知道它的位置,所以要进行 new 操作:它返回的是这块新创建内存地址。
- 在 Java 中,内存地址是 64 位的。
- 例如:如果对象被创建在内存位置 2384723423,那么 new 就会返回 2384723423。
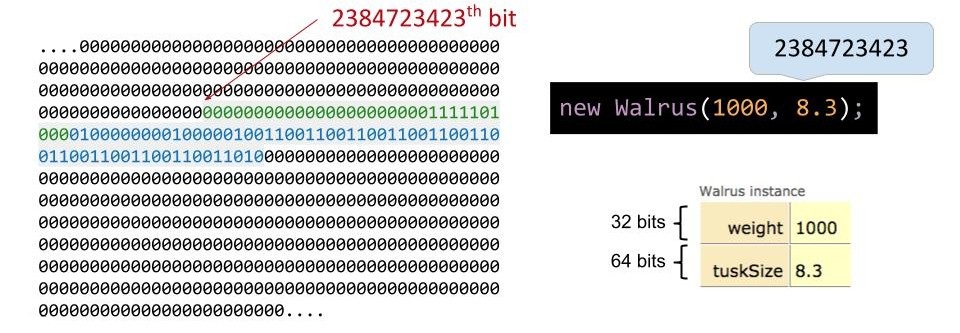
我们现在知道了海象的位置,接着我们得把它记下来!
引用类型变量的声明(等号左边)
当我们声明一个任意引用类型的变量,如 Walrus someWalrus; 时:
- Java 会分配一个 64 位大小的盒子
- 盒子中的位可以被设置为:
- Null(全为 0)
- 某个类的实例的 64 位地址(由
new返回)
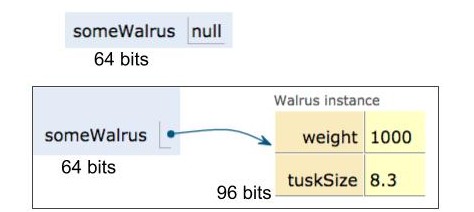
究其本质,引用类型的变量存储的并不是该对象的实体,而是对该对象的引用(也就是地址)。
引用类型同样遵循等号黄金法则
搞清楚了上面的内容,b = a 的操作本质上也只是将 Walrus a 对 Walrus(1000, 8.3) 实体的引用复制出一份副本给了 Walrus b。

Walrus a 与 Walrus b 指向的都是同一个实体,那么通过 Walrus b 修改 Walrus 实体自然会影响通过 Walrus a 访问 Walrus 实体的结果。我想我们解开了海象谜团。
参数传递
当你在尝试将变量作为参数传递给方法的时候,虽然你并没有在 x 与 a 之间看到什么等号,但等号的黄金法则仍然奏效。
public static double average(double a, double b) { |
伴随着方法的调用,x 与 y 被分别复制出一份副本到 a 和 b 中,这便是值传递(Pass by Value)。其中 a 与 b 是形参(parameter),x 与 y 是实参(argument)。
而对于对象类型的参数,Java采用的是引用副本传递(Pass by Copy of Reference):
- 方法接收的是引用的副本(即内存地址的拷贝);
- 可以通过这个引用修改对象的内容;
- 但对参数重新赋值不会影响原始引用。
class MyObject { |
真正的引用传递(Pass by Reference)如 C++ 的引用参数(&),允许方法内对参数的修改(包括重新赋值)直接影响原始变量。
数组
我们再来简单了解一下数组:
数组并不是基本类型,所以想要创建一个数组时,也要使用 new 关键字,并像其他对象一样将数组实例化。
Planet p = new Planet(0, 0, 0, 0, 0, "blah.png"); |
对于字符串数组,数组中将不会存储每个字符串而是每个字符串的地址,因为字符串不是基本类型。
列表(Lists)
不同于 C++ 中的 vector,在 Java 中,数组有固定的大小。当我声明有一个大小为 5 的新数组时,它的大小将永远是 5,不能添加更多的元素。
那么如果我想要一个大小可以随着我添加的数据增加而变大的这种数据结构呢?
所以让我们开始构建 列表 的旅程吧。
数组(Arrays)
我们花了一些时间利用链表完成了列表的构建,但这只是一种为我们的用户提供列表的方法。所以从现在开始,我们要从头开始建立一个全新的列表类型,但这次我们将使用 数组 作为底层数据结构而不是节点和链接。
继承(Inheritance)
接口继承(Interface Inheritance)
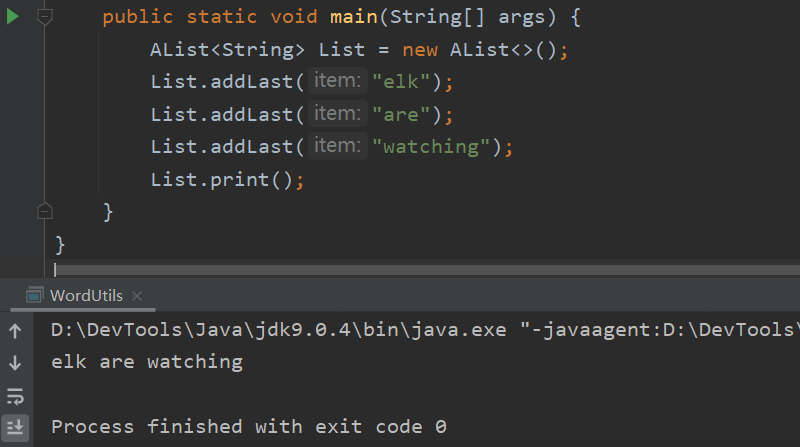
目前我们已经实现了我们的 SLList 和 AList!而当用户使用时通常会将他们使用的数据结构作为参数传递到方法中:
// File: WordUtils.java |
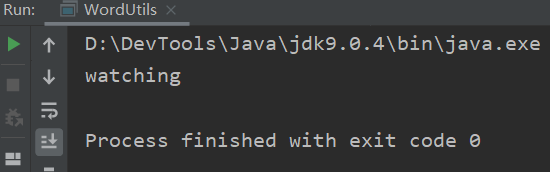
但用户肯定不总是想用 SLList 来实现这个操作,如果我们换成是 AList,编译器又不高兴了:
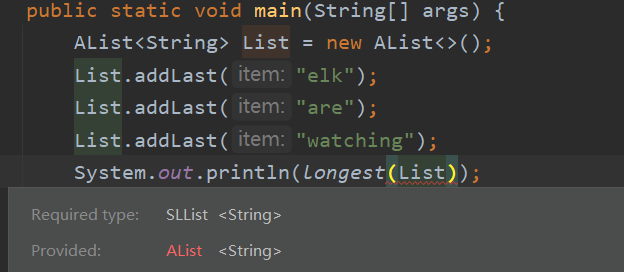
这个问题该如何解决?再复制一个 longest 方法并将参数换成 AList 就好了:
// File: WordUtils.java |
方法名相同但参数不同,称为方法的 重载(Overload) 。
虽然重载能解决目前的问题,这并不是一个好主意,因为:
- 相同的代码重复了两次,看起来有点恶心;
- 如果以后又创建了
DList、QList,又不得不复制出第 3 个、第 4 个方法; - 难以维护:如果在被重载的方法中发现了 bug,其它的方法也同样需要修复。
还有什么解决方法呢?
实现抽象方法
上位词(Hypernym)与下位词(Hyponym)
给贵宾犬和给阿拉斯加洗澡的步骤都是一样的:梳好毛、放好热水、打好香皂、冲干净、吹干······所以我们可以用一个上位词“狗”来代替各种狗的品种。
那我们可以把同样的思路应用在 Java 上吗?
接口(Interface)与实现(Implements)
因为SLList 与 AList 都具有相同的用户交互方法,所以 SLList 与 AList 都是 List61B 的一种,List61B 便是 SLList 和 AList 的上位词。
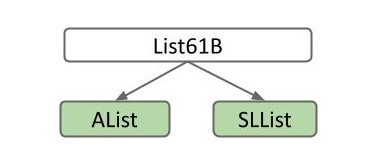
明确了这点后,对于上位词,我们不用关键词 class 而是改用 interface 来定义。
- 接口内包含了一系列没有方法体的 抽象方法 ,指定了 List61B 能做什么,而不是具体去实现。
// File: List61B.java |
接着我们要用关键词 implements 告诉 Java 编译器 SLList 和 AList 是 List61B 的下位词(子类)。
- 子类须要对接口内的抽象方法进行具体实现。
// File: AList.java |
下面就可以直接在要实现的方法中直接使用接口了:
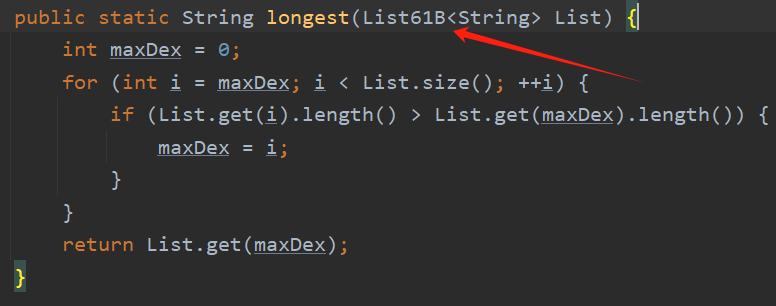
重写(Override)与重载(Overload)
- 子类重新定义父类中已有的方法且方法签名完全一致称为 重写 ;
- 同一个类中方法名相同但参数不同称为 重载 。

用 @Override 注释可以显示标记重写方法,提高可读性。
- 即使不写 @Override 子类仍能够重写方法,@Override 只是一个对重写方法的标记;
- 使用 @Override 的主要原因是避免输入错误。如果写了 @Override 但方法并没有进行重写,编译将会出错。
接口继承
我们刚刚所做的一切便是接口继承(Interface Inheritance):
- 接口:所有方法签名的列表;
- 继承:子类“继承”接口;
- 接口指定子类实现的方法而不去实现;
- 子类必须重写所有方法,否则编译将会出错。
思考题:下面的代码能够编译吗?如果能,它运行时将发生什么?
public static void main(String[] args) { |
答案:When it runs, an SLList is created and its address is stored in the someList variable. Then the string “elk” is inserted into the SLList referred to by addFirst.
继承 default 方法
直接继承 default 方法
对于接口继承,除了实现抽象方法,Java 还允许继承 default 方法:子类不仅能继承方法签名,还有方法的具体实现。
使用关键字 default 来指定子类能够从接口继承的方法。
举个栗子:让我们再给 List61B.java 实现一个 print() 方法!
// File: List61B.java |
这样即使子类(如 AList)中并没有实现 print() 方法,也可以直接调用这个方法了:
但是现在又回到了我们曾经实现这些数据结构时遇到的问题:效率问题。这个接口提供的默认方法对所有子类来说都是高效的吗?size() 方法直接返回实例变量 size,很高效;get() 方法对 AList 来说直接返回数组下标对应的元素,很高效,但对 SLList 来说每次都要从头遍历一次链表,很慢所以要针对 SLList 进行改进。
重写 default 方法
如果你不喜欢一个接口中的 default 方法,你可以在其子类中对其进行重写,这样任何对该子类中该方法的调用都会直接调用重写的方法而不是 default 方法。
// File: SLList.java |
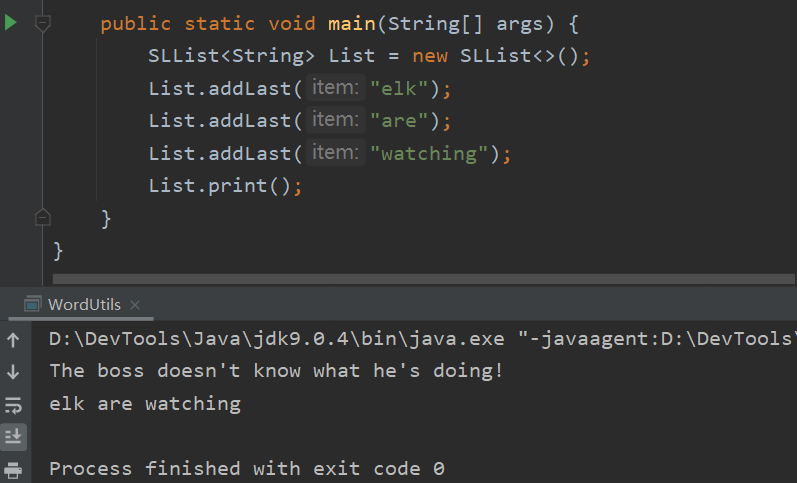
Static and Dynamic Type
是什么导致运行 List.print() 时调用的是 SLList 中的 print() 而不是 List61B 中的 print() 呢?这就不得不提到 Java 的两个类型:
compile-time type(static type):
- 是变量在声明时的类型,在声明时被指定,且无法改变;
- 编译器在编译代码时使用的类型;
- 决定了哪些方法和属性可以被访问。
run-time type(dynamic type):
- 是变量在运行时实际指向的对象类型,在实例化时被指定(如 new),可以改变;
- 在程序运行期间确定的类型;
- 决定了实际调用哪个方法实现。
如:

具体在下节中讨论。
实现继承(Implementation Inheritance)
extends 关键字
除了上面介绍的,我们除了可以对接口 interface 进行继承,还可以直接对类进行继承,这时我们就要用到关键词 extends。
旋转单链表
举个例子:现在我想基于 SLList 再构建一个 RotatingSLList,使得能够将链表的最后一个元素移动到开头。
例如:我们链表中已经有了 [10, 11, 12, 13]
rotateRight 一次:[13, 10, 11, 12]
// File: RotatingSLList.java |
托福于 extends 关键字,我们得以从 SLList 继承所有的成员:
- 所有实例与静态变量;
- 所有方法;
- 所有嵌套类。
复仇单链表
再举个例子:我们现在想再实现一个单链表,使得:
- 能够记忆所有通过
removeLast()删除的节点的值; - 有一个额外的
printLostItems()方法能够打印出所有已删除的节点的值。
// File: VengefulSLList.java |
首先我们得有一个地方存储我们删掉的节点:
private SLList<T> lostItems; |
接着把这些节点打印出来:
public void printLostItems() { |
但是还有一个问题,我们如何向这个 lostItems 中添加节点呢?既然 lostItems 中存储的是 removeLast() 删除的节点,那么 removeLast() 方法仅仅删除原链表的节点是不够的,还要向 lostItems 中添加删除的节点,因此我们要重写该方法。
但是如果我们尝试将 SLList 里的 removeLast() 方法复制过来,一些问题产生了:
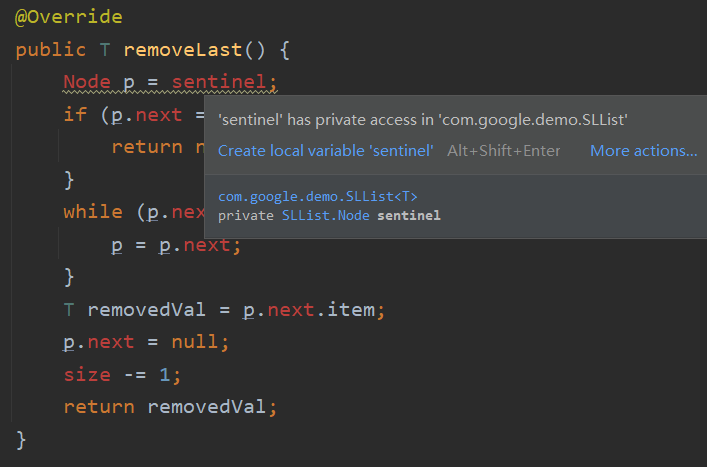
Node 是 private 的、sentinel 是 private 的、size 也是 private 的······private 是如此私有以至于子类都无法访问。
这时候我们就要引入一个新的关键字 super,它是对父对象的引用。有了这个关键字,我们就可以直接使用 SLList 的 removedLast() 方法而不用把它复制过来了。
|
构造器
回到我们之前提到的没有被继承的构造器。当我们调用子类的构造器时究竟发生了什么?我们不妨在调用子类的构造器处打一个断点然后 debug:
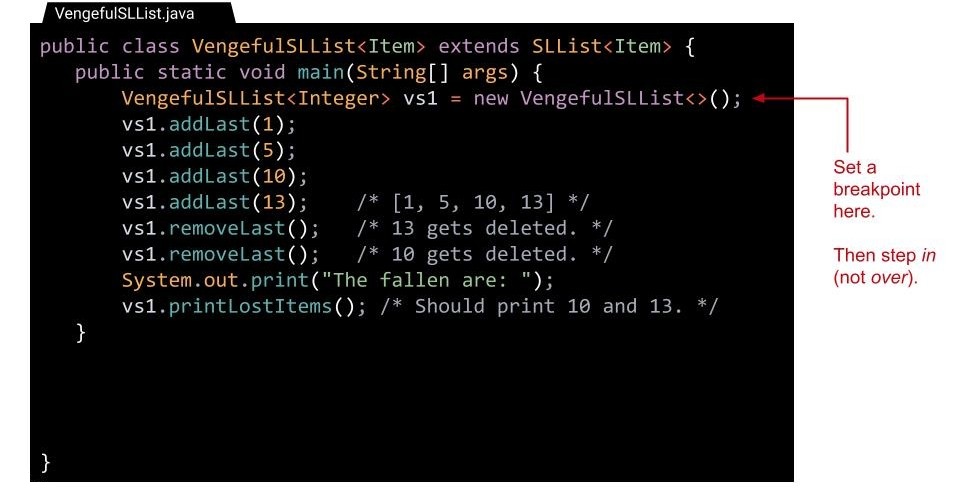
事实证明,所有构造器都必须首先调用父类的某个构造器。
- 你可以用关键字
super明确地调用构造器; - 或者 Java 会自动为你这样做。

如果要调用带参数的构造器,就给 super() 传递一个参数。

实现继承
总结一下上面学到的内容:
Java的继承分为两大类:
- 实现继承(类继承):通过
extends继承父类的具体实现(属性和方法)。 - 接口继承:通过
implements实现接口的抽象方法或继承default方法。
- 实现继承
- 核心:子类复用父类的代码实现(包括字段和具体方法)。
- 用途:代码复用。
- 特点:
- 单继承(一个类只能继承一个父类)。
- 子类可以重写父类方法(@Override)。
- 父类的私有成员虽然会被继承,但无法直接访问。
- 在创建子类对象时,父类的构造器会被优先调用(显式或隐式),从而完成父类私有字段的初始化。
- 可通过父类提供的 public/protected 方法间接访问。
- 接口继承
- 核心:子类实现接口的抽象方法或继承
default方法。 - 用途:定义行为契约,规范行为。
- 特点:
- 多继承(一个类可实现多个接口)。
- 接口中的
default方法提供默认实现,子类可选择重写。 - 接口无状态(不能有实例字段)。
字段(Field):字段是类中定义的变量,用于存储对象的数据。它们是对象的“属性”或“成员变量”。
状态(Status):状态是对象在某一时刻的所有字段值的集合,表示对象的“当前状况”。
Object 类
事实上,Java 中你定义的每一个类,无论是 Dog,IntList,SLList,还是 Walrus,即使你没有说过 extends Object,都是 Object 类的子类。
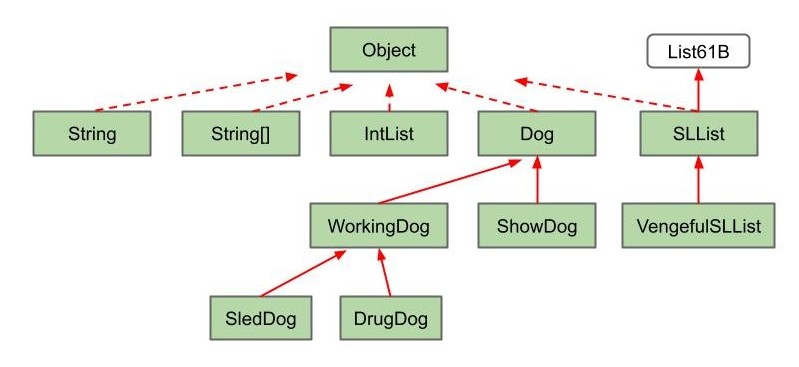
所以所有类也都继承了 Object 的方法:
Is-A vs. Has-A
“继承”这一特性只应被用于处理“Is-A”关系而不是“Has-A”关系,例如 SLList Is-A List61B、RotatingSLList Is-A SLList······错误地使用“继承”将导致一系列麻烦。举个例子:
栈(Stack)是另一种美妙的数据结构,能够实现一些方法:
push(x):将x放在栈顶;pop():删除并返回栈顶元素。
如果利用“栈有一个链表”的关系来实现栈:
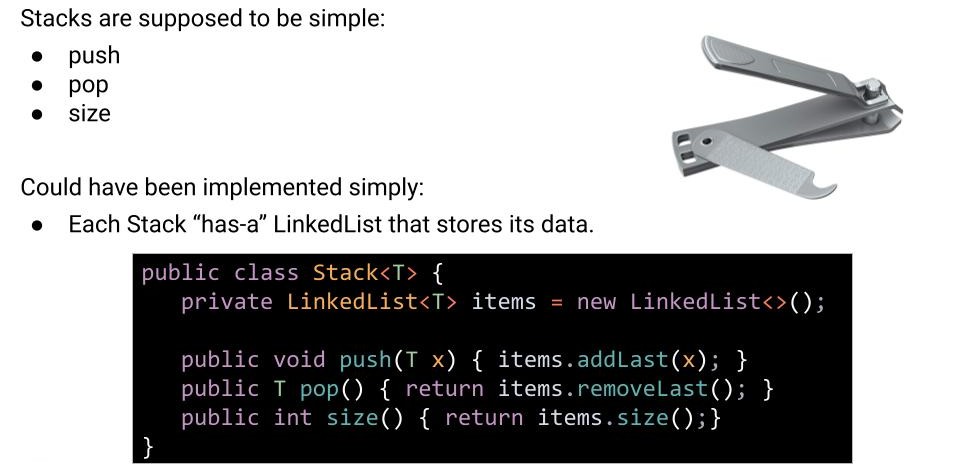
一切都是如此简约和恰到好处。
但如果利用“栈是一个链表”这个关系来实现栈:

结果就是栈从链表那继承了一堆本不需要的方法。
封装(Encapsulation)
当我们构建大型程序时,我们的敌人是复杂性。如果你必须要一次性记住所有的事情,那你将十分痛苦。为了有效地构建大型程序并成为一名优秀的程序员,学习如何管理复杂性是必要的。
封装的核心思想是:
把数据(属性)和对数据的操作(方法)绑定在一起,并对外部隐藏实现细节,仅暴露必要的接口。
简单来说,就像我们不需要知道一辆车是如何被造出来的,只要会开就好了,因此显著降低了开车的难度。
对程序而言也是如此:
- 对内部而言,只需要提供外部需要的接口就好了。同时将字段设置为私有,外部也无法干扰内部的具体实现。
- 对外部而言,只需要使用对应的接口就好了,不需要关心内部的具体实现。
而 Java 便是通过 访问控制符 + 方法访问 来实现封装的:
- 使用
private修饰成员变量:将类中的成员变量设置为私有,外部无法直接访问。 - 提供
public的 getter/setter 方法:通过公共方法暴露对属性的受控访问接口。
例如:
public class Person { |
这段代码中 name 便是私有属性,外部无法直接访问;getName() 便是 getter 方法,对属性值进行获取;setName(String name) 便是 setter 方法,对属性值进行设置。
实现继承破坏了封装
但当封装遇到了实现继承可能会发生某些意料之外的问题。例如:
public class Dog { |
public class Dog { |
这两段代码的功能完全一致,但当遇到了实现继承:
public class Dog { |
public class Dog { |
要知道封装意味着外界用户永远无法得知 Dog 类的内部实现,只能通过接口与其进行交互;改变 Dog 的私有实现也不应该影响 Dog 类的外界用户。
但在运行主方法时,第一段代码能够正常输出,但第二段却陷入了在 bark() 和 barkMany() 之间反复横跳的无限循环中。
类型检查与转换
还记得上节我们谈到的静态与动态两个类型吗?
Java 会基于静态类型进行类型检查,基于动态类型选择实际要调用的方法。
public static void main(String[] args) { |
要点说明:
- 方法调用与类型检查
sl.removeLast(); |
编译器阶段:
- 编译器看到
sl的类型是SLList,查找SLList类是否有removeLast()方法。 - 找到了,类型检查通过,所以允许调用。
- 此时编译器并不知道实际调用具体哪个类的
removeLast()来实现(SLList还是VengefulSLList)。
JVM 运行时:
- JVM 根据
sl的运行时类型(VengefulSLList)走虚方法表*。 - 它在
VengefulSLList的虚方法表中查找removeLast()的真实方法地址,并跳转执行它。 - 所以调用的是
VengefulSLList的removeLast()方法,而不是SLList的。
*虚方法表(vtable)是一个数组结构,存放着该类所实现的“虚方法”的指针。也就是说,对于每一个类,JVM 会构建一张表,把所有实例方法(可被重写的方法)、重写父类的方法、从父类继承的方法的实际实现地址存在里面。
- 向上转型(Upcasting):将子类对象引用转换为父类类型引用
SLList<Integer> sl = vsl; |
- 这个关系就像在说复仇单链表是单链表。
- 向上转型是安全的,因为子类对象继承了父类的所有成员,Java 会自动完成隐式转换。
- 转型后只能访问父类中定义的成员,但由于动态绑定*,执行的仍然是子类中重写的方法。
*动态绑定指的是在运行时决定调用哪个方法的行为,而不是在编译期间就确定。动态绑定是实现 Java 多态的核心机制。
- 向下转型(Downcasting):将父类类型引用转换回子类类型引用
VengefulSLList<Integer> vsl2 = sl; |
- 这个行为就像在说这个单链表是复仇单链表。
- 不安全,需要显式转换和类型检查,且父类类型引用必须指向目标子类,否则会抛出
ClassCastException。 - 通常要配合
instanceof判断使用。
if (sl instanceof VengefulSLList) { |
高阶函数
高阶函数(Higher-Order Functions, HOFs):将其他函数作为参数(或返回函数作为结果)的函数,例如:
def tenX(x): |
而 Java 要想实现这个功能,对于旧版本(Java 7 及以前)需要 3 个类:一个接口类,用于提供调用的接口;一个实现类,实现接口的抽象方法;一个主类,里面有实际调用的方法,会接收一个接口和变量作为参数。(其实干脆不用接口也行)
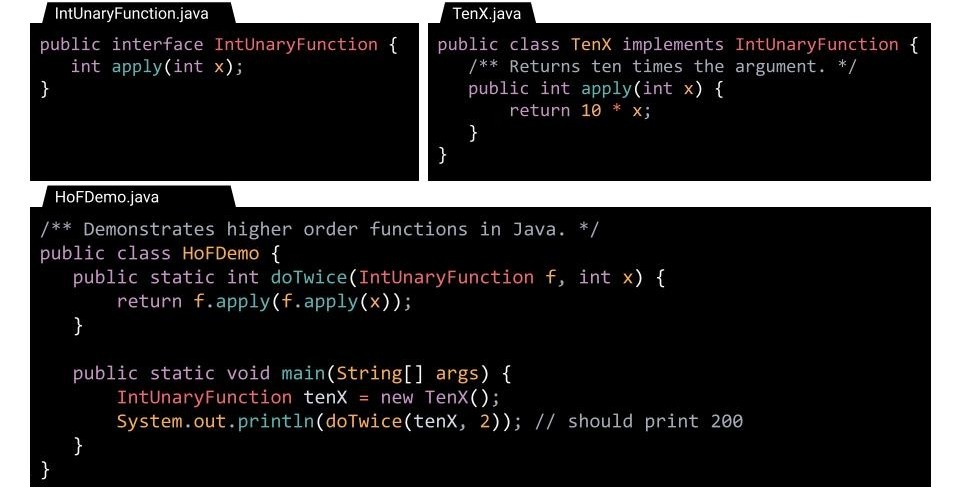
但对于 Java 8 及以后的版本,可以直接持有对方法的引用而不需要通过接口间接调用方法了,但对此不会过多赘述。
子类型多态(Subtype Polymorphism)
子类型多态 vs. 显式高阶函数
前面我们讲的主要内容就是关于 子类型多态 。
- 多态:为不同类型的实体提供一个统一的接口。
- 子类型多态:父类引用指向子类对象、运行时动态绑定。
但并非所有语言都有子类型多态。它们不会通过动态绑定来调用函数,而是显式地传递函数以在高阶函数内使用。

Callback(回调函数)是一种编程模式,将一个函数 A 作为参数传递给另一个函数 B,并在函数 B 的特定条件满足时调用函数 A。它的核心思想是“由被调用方(函数 B)决定何时执行传入的函数”,而不是由调用方直接控制。
泛型的 Max 方法
接下来让我们构建一些东西来体会子类型多态的力量吧:
现在我们想写一个方法 max() 能够返回 任何类型 的数组中的最大值。
我们先来看看这个实现有什么问题:
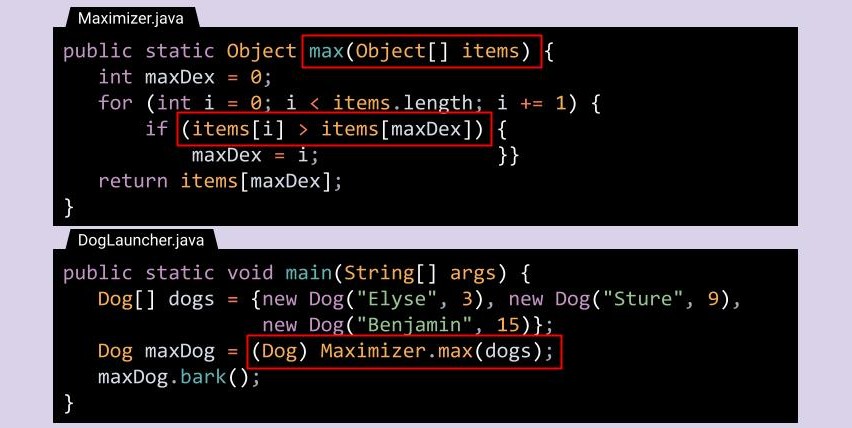
max(Object[] items):之前我们讲过,任何类都是Object类的子类。因此,这样写任何我们想比较的对象都可以被作为参数传入max()方法中,没什么问题;(Dog) Maximier.max(dogs);:如果我们传入的对象是Dog类的,那么max()方法返回的也是Dog类,因此进行类型转换也没什么问题;(items[i] > items[maxDex]):啊哈,问题在这:并不是所有的对象都可以直接用“>”比较,至少要给出比较的依据呀?是根据Dog的size大小?name首字母?甚至是“蓬松程度”?
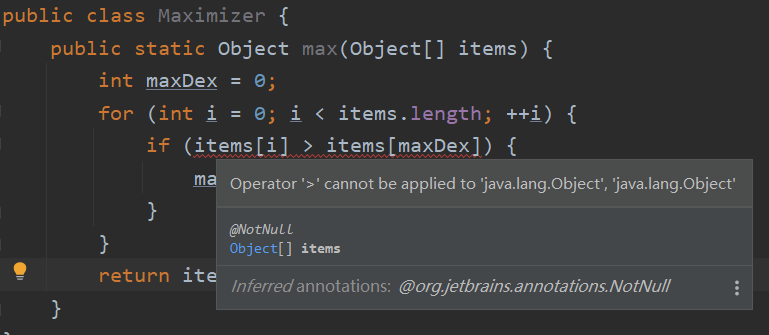
对于这个问题,我们可以在 Dog 类中提前写好比较的方法:
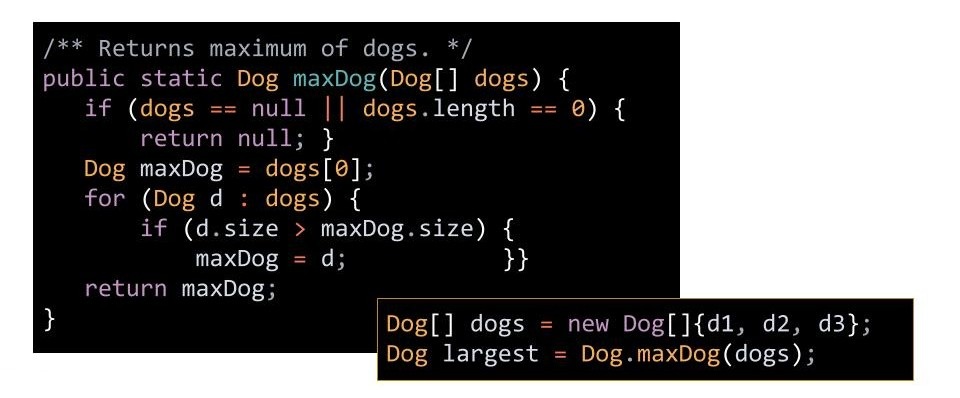
但这样做就需要我们只要有一个存在比较需求的类,就要为其单独写一个比较的方法,违背了我们当初的意愿:设计一个能返回 任何类型 的数组中的最大值的方法。
我们的 Comparable
这时候我们就要创建一个接口来保证一个统一的比较方法:
- 让
Dog实现这个接口 - 以接口的形式写
Maximizer类的max()方法
// File: OurComparable.java |
问题确实解决了,但还有几个问题:
- Override 的
compareTo()方法有点长有点屎; Dog与Object之间的类型转换有点尴尬且存在隐患;- 目前实现
OurComparable接口的类只有Dog,除非重写整个 Java 标准库让所有类都实现该接口,否则这个方法将不会特别通用;
问题一:其实我们可以这样写:
public class Dog implements OurComparable { |
这样返回的就不是 +1 或 -1 而是正数或负数了。事实上,真正的 Java 程序员也在应用这个技巧。
对于问题二和问题三,事实上,Java 提供一个内置的 Comparable<T> 接口供我们使用,其中包含一个抽象方法 public int compareTo(T o);。
Comparable

我们的 Dog 类就变成:
public class Dog implements Comparable<Dog> { |
在足够通用的基础上也减少了一些不必要的类型转换。
记得将其它 OurComparable 也替换为 Comparable。
Comparators
值得注意的是上面我们实现的比较方法 compareTo() 需要用被比较的对象自身来调用以完成与同类的其他对象的比较:items[i].compareTo(items[maxDex]);,这意味着 compareTo() 方法必须要在类内对 Comparable 接口进行重写实现。但在同一个类中对同一个方法签名只能重写一次,所以这种比较方法只能定义一种。这种排序方式被称为 自然排序(Natural Ordering)。自然排序通常会选择一种默认的方式进行排序,如比较狗的重量,而不是狗的名字。
但如果我们还想比较狗的名字该怎么办?没关系,此时我们还有 Comparator!
Comparator<T> 是 Java 中用于比较两个对象的接口,包含一个抽象方法:int compare(T o1, T o2);
// File: NameComparator.java |
事实证明这完全没问题:
不过在实际的 Java 程序中 Comparator 并不是这个样子。事实上:
NameComparator事实上是Dog的一个从属功能,所以像LinkedList的Node一样,NameComparator不会作为一个独立的类,而是作为Dog类的一部分——嵌套类而出现。NameComparator不同于size和name,不是某个小狗对象的属性而是整个Dog类的功能,所以应该被声明为static。- 外界并不关心
NameComparator的内部实现,所以我们要将其封装起来,再对外开放一个接口方法。
我们终于得到了我们的最终版本:
// File: Dog.java |
由于我们无法再直接访问 NameComparator 了,使用时需要:
Comparator<Dog> nc = Dog.getNameComparator(); |
有了 Comparator,我们就可以任意定制任何我们想要的排序规则了!
迭代器(Iterators)
这一节我们的目的是构建一个被称作 ArraySet 的集合。
- 集合中的元素没有顺序
- 集合中的元素不能重复
起初,一个 ArraySet 需要包含如下方法:
add(value):向ArraySet中添加一个当前不存在的元素;contains(value):查看当前ArraySet是否存在该键;size():返回当前元素数量。
// File: ArraySet.java |
接着我们就可以为我们的 ArraySet 添加一些花哨的功能了。
Iteration
The Enhanced For Loop
首先我们先讲一点语法知识,你可能在某些地方看到过类似于这种语法并感到困惑:
Set<Integer> javaset = new HashSet<>(); |
我也是前面学算法的时候才见过这个东西。事实上,这段 for 循环相当于:
Iterator<Integer> seer = javaset.iterator(); |
好像还是挺难懂的,我们再解释一下:
- 第一行
Iterator<Integer> seer = javaset.iterator();为我们创建了一个迭代器seer,相当于一个指针,它指向javaset对象的第一个元素; hasNext()会为我们检查当前指向的位置是否有值;next()会返回当前指向位置的值,并将指针移到下一个位置。
说白了 iterator 就是采蘑菇的小姑娘,hasNext() 会看看脚下有没有蘑菇,next() 会采下蘑菇再往前走一步。
那当我们想将这位小姑娘请到我们的 ArraySet 中呢?
iterator, next, hasNext for ArraySet
事实上,与 Comparator 一样,Java 也为我们提供了 Iterator 接口,所以我们要做的与写 Comparator 一样:写一个私有类负责实现接口,用一个 getter 返回 Iterator,最后就可以在主方法中使用了。
// File: ArraySet.java |
这是直接写在 ArraySet 类内的,当然你也可以单独写一个类,只需要为 size 和 items 额外写两个 getter 就好了。
Iterable
我们成功地把小女孩请了进来,但是这只是个底层的实现逻辑,我们真正使用时更期望用上更简洁的 Enhanced For Loop。但直接生搬硬套是不行的:
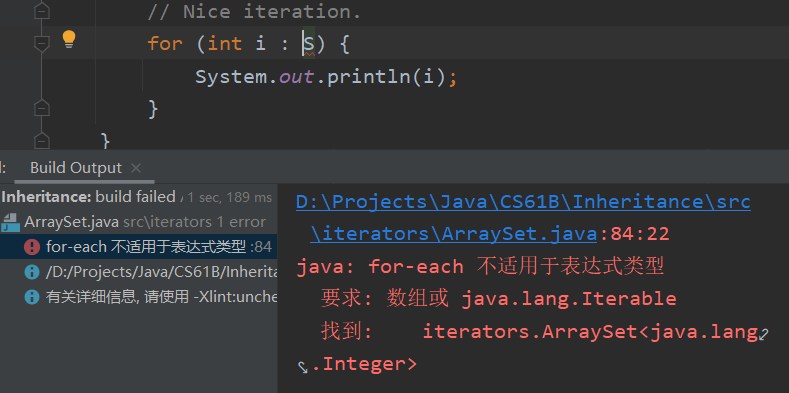
虽然有了迭代器,Java 并不知道我们的 ArraySet S 是可以迭代的,所以我们得用什么咒语告诉它。事实上,与 Comparable 相同,Java 也为这些可迭代的类内置了统一的接口 Iterable:
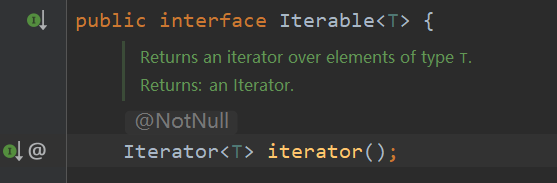
我们只要实现并重写这个接口的方法就好了。
public class ArraySet<T> implements Iterable<T> { |
总结一下
Iterable 和 Iterator 是紧密合作的一对接口,但它们职责不同:
Iterable:
- 含义:表示 “可迭代的集合本身”。
- 方法:
iterator()。它负责创建并返回一个新的迭代器对象。 - 比喻:就像一本 书(Iterable),它提供了一个方法让你拿到一个 书签(Iterator)。
Iterator:
- 含义:表示 “迭代器本身”,是真正的遍历执行者。
- 方法:
hasNext(),next()。它负责实际执行遍历操作,告诉你是否还有下一页(hasNext()),翻到下一页并返回内容(next())。 - 比喻:就像那个 书签(Iterator),它记得你读到哪了,并能帮你翻到下一页。
关系总结:Iterable 是源头,它生产 Iterator。Iterator 是工具,它消费 Iterable 中的元素。
Object Methods
还记得我们之前提到所有类都是 Object 类的一部分吗?所以所有类都继承了 Object 的方法,接下来我们尝试利用几个方法为我们的 ArraySet 增加几个功能。
toString
先思考一个问题:我们一直以来使用的 System.out.println(Object x) 方法是如何为我们打印出我们想要的东西的呢?
答案是 pintln() 方法会调用 String.valueOf() 方法,最终调用 toString() 来将参数转换为要打印的字符串。
而我们如果直接打印我们的 ArraySet,结果并不会与我们预料中的一致,因为我们的 ArraySet 还没有实现 toString() 方法,用的是直接从 Object 那继承来的。
所以现在让我们实现一下吧:
|
可以看到我们能够正常打印出 ArraySet 了,但是这种实现方法不太好,因为字符串是不可修改的常量。当你用 “+” 尝试将几个字符串加在一起时,你是实际上是在创建一个新的字符串,这意味着实际上是将需要合并的字符串都复制到一个新的字符串中。有点像我们实现 ArrayList 的 resize 时遇到的问题,当字符串很长的时候这样做很慢。
为了解决这个问题,我们引入一个新的对象 StringBuilder。当向字符串中添加字符串时调用 append() 方法即可。
|
== vs. equals
谈到比较两个对象是否相同,我们第一个想到的就是 “==” 运算符。== 运算符会比较两边的比特位是否完全一致。现在我们想比较两个 ArrayList 是否一致,先用它试试看:
public static void main(String[] args) { |
显然,结果是 false。因为 S 和 S2 都是引用类型的变量。即使它们分别指向的内存位置存储的东西从某些方面来说是相同的,但它们指向的内存位置不同,结果就是不同的。
事实上,我们也从 Object 那继承来了用于比较的方法 equals(),但直接使用的结果与刚才没什么区别。
System.out.println(S.equals(S2)); |
因为 equals() 默认也是用 == 实现的。
所以让我们重写一个 equals() 方法:
|
前面我们简单提过,instanceof 关键字会检查 o 的动态类型是否是 ArraySet。
当然如果你是用的是 Java 16 或更高的版本,可以使用:
if (o instanceof ArraySet otherArraySet) { |
来直接取代上面的强制类型转换。
现在运行,我想我们就能得到我们想要的答案了。
渐近分析
学完 CS 61B,我们希望能够实现从“programmer”到“engineer”的蜕变。
也就是说,不仅需要从编码方面,更要从代码的执行层面上考虑问题,如:你的程序执行要花费多长时间?你的程序需要消耗多少内存?
所以我们还需要一些渐近分析的能力。
并查集(Disjoint Sets)
前面铺垫做得差不多了,接下来我们终于可以着手解决一系列经典的数据结构的问题了。
这一节,我们将针对“动态连通性”问题,推导 并查集 数据结构。我们将看到:
- 数据结构设计如何从基础形态逐步演进为复杂实现;
- 底层抽象的选择会如何影响算法时间复杂度(使用严谨的大Θ符号表示)与代码复杂度。
集合与映射(Sets & Maps)
抽象数据类型(Abstract Data Types)
也许你对这个观点感到无比厌倦:我们在继承章节中强调过,接口指定了能做什么,而不是具体去实现。
而抽象数据类型的主旨也是如此:它强调数据的逻辑行为和操作,而非具体的实现细节。ADT 定义了数据的“是什么”(功能),而不关心“如何做”(具体实现)。
例如前面我们用 AList 和 SLList 两种方式实现了 List61B,用 ArrayDeque 和 LinkedListDeque 实现了 Deque,甚至用 QuickFindDS、QuickUnionDS、WeightedQuickUnionDS 和 WQUwithPathCompression 四种方式实现了 DisjointSets。其中的 List61B、Deque、DisjointSets 便是抽象数据类型。
除此之外,常见的 ADT 还有:栈(Stack)、集合(Set)、映射(Map)。栈前面我们简单提到过,栈底层也是通过数组或链表来实现入栈 push(int x) 和出栈 int pop() 操作,在这里我们也不过多赘述了。
接下来我们将着力于对集合和映射的实现。
二叉搜索树(Binary Search Trees)
不过在此之前,请先允许我们介绍一下计算机领域中最巧妙的想法之一:
集合与映射
人们往往沉溺于 BST 概念的美好中而忘记了引入 BST 的目的:构建一个无序的、不重复的项目集。
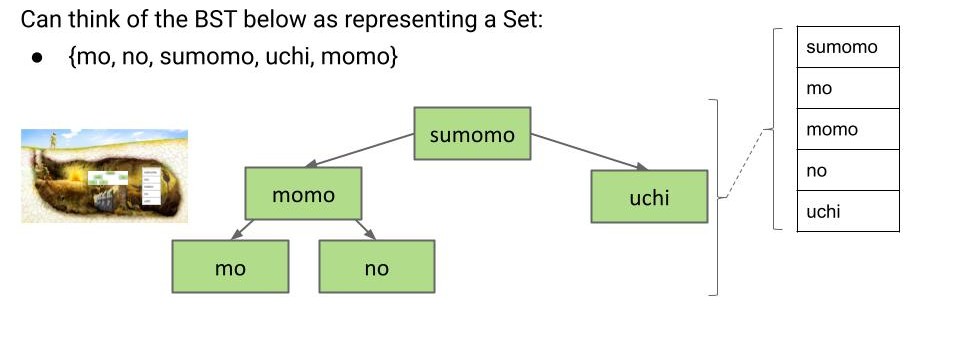
除了存储独立的元素,还可以存储键值对,此时集合就变成了映射。
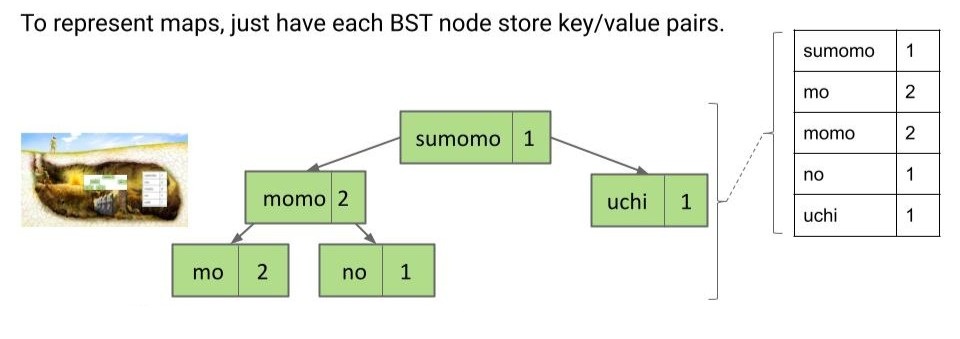
对于映射,只能通过键来查找值,而不能通过值来查找键。例如如果不遍历所有节点,无法找到所有值为 1 的键。
值得一提的是,虽然集合是无序的,但 BST 是有序的,这并不冲突。因为用户不在乎顺序并不意味着我们不能利用某种顺序来加快我们的速度。
利用 BST 实现映射的部分请查看 Lab 7: BSTMap
哈希表(Hash Tables)
之前我们已经见过了集合与映射的几种实现:
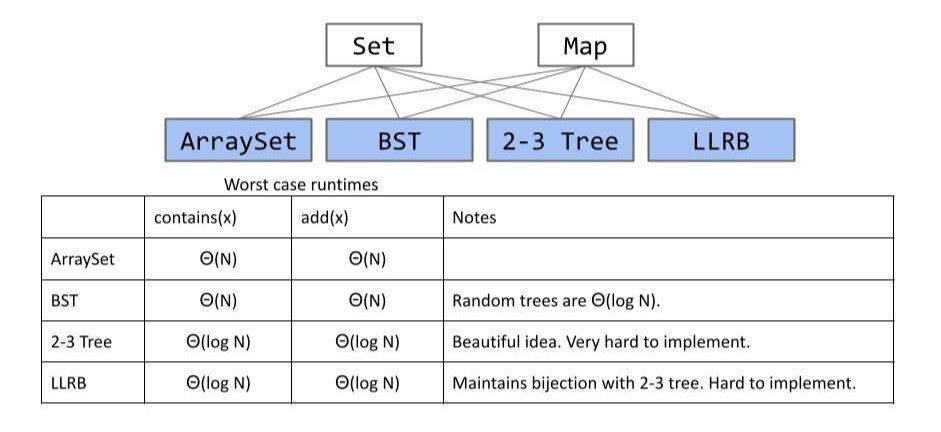
但我们目前的方式仍有一些缺陷:
- 键值必须是可比较的。
- 像我们在 lab7 中实现的 BSTMap,K 必须要
extends Comparable<K>。我们需要问一些像“X 比 Y 小吗?”这样的问题,但它并不适用于所有的类型。如果我们有一些像对象、狗狗照片之类的东西,这些东西是没法比较的。
- 像我们在 lab7 中实现的 BSTMap,K 必须要
- 目前基于搜索树的集合(映射)实现的性能很好,10 亿个节点的树的高度只有 30。但能不能做得更好?
堆与优先队列(Heaps & Priority Queues)
在过去的几节中,我们讨论了用 BST、哈希表等实现集合和映射的几种不同方法。
而接下来,我们将讨论一种全新的 ADT——优先队列。
堆与优先队列(Heaps & Priority Queues)
图与遍历(Graphs and Traversals)
前面的课程中,我们讨论了一系列核心数据结构。所有数据结构都有一个共同点,就是用户可以将一个新元素添加到一个元素堆中,而数据结构的任务就是维持这个元素堆的有序性。也正是这个有序性,使得用户能够高效地从中检索任何元素。

而接下来的课程中,我们将介绍另一种重要的数据结构——图。


