数组(Arrays)
数组概述
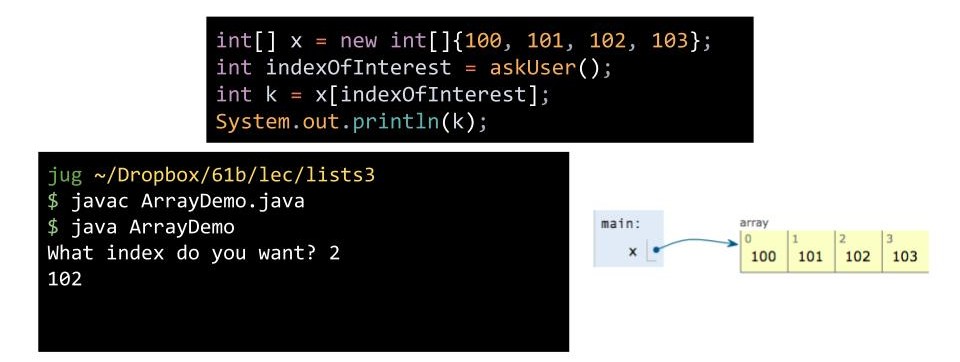
为了存储数据,我们需要内存盒子,这样就需要我们声明变量或实例化对象。例如:
int x;会给我们一个 32 位的盒子存储int;Walrus w1;会给我们一个 64 位的盒子存储Walrus的引用;Walrus w2 = new Walrus(30, 5.6);既会给我们一个 64 位的盒子存储引用,又会给我们一个 96 位的盒子用来存储Walrus中的int和double型变量。
而我们接下来讨论的数组 Array 类似于对象,但不同的是数组中的内存盒子依赖于编号而不是命名。
当你声明一个五个元素的数组时,Java 将返回一段能容纳五个元素的连续的区域,且这个区域永远不会改变。因此一个长度为 N 的数组包含:
- 一个固定的整数长度 N
- 数量为 N 个的内存盒子
- 所有盒子存储相同类型的值
- 每个盒子被分别编号为 0 ~ N - 1
与对象相同的是:
- 当数组被创建时你会得到一个引用;
- 如果你修改了所有包含这个引用的变量,你将永远找不回那个数组了。就像是如果你弄丢了你的藏宝图,你就永远找不到你的宝藏了。
而不同于对象,数组没有方法。
数组的基本语法
如果你不是一个数组专家,那就像类一样用 new 关键字来实例化。
三种合法的表示法:
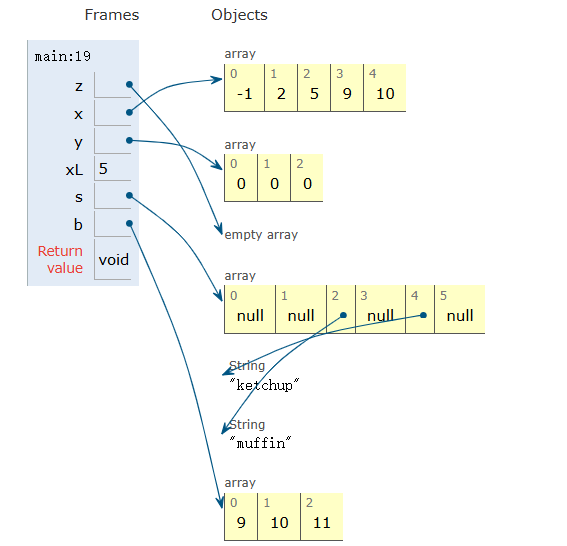
x = new int[3]; // 创建一个包含 3 个整型元素的数组y = new int[]{1, 2, 3, 4, 5};int[] z = {9, 10, 11, 12, 13}; // 熟练了也可以不用 new
接着你可以尝试搞明白下面的代码在内存中分别做了什么事情?
public class ArrayBasics { |
数组的复制
有两种方法:
- 可以利用循环遍历数组复制;
- 利用
arraycopy函数复制,需要传入 5 个参数:源数组及其起始下标、目标数组及其起始下标、复制元素的个数。
尤其对于大数组,利用 arraycopy 函数复制会更快些,但也难以阅读。
二维数组
二维数组就是以数组为元素的数组,所以每个元素存储的是对数组的引用。
int[][] pascalsTriangle; // 声明 |
pascalsTriangle = new int[4][]; // 实例化并赋值 |
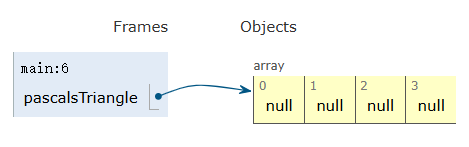
// 为每个数组元素赋值 |
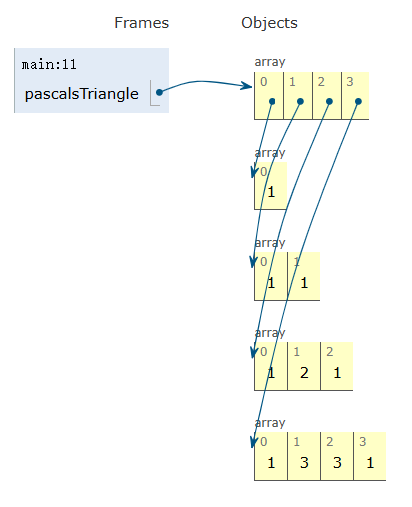
// 当然你也可以声明、实例化、赋值一气呵成 |
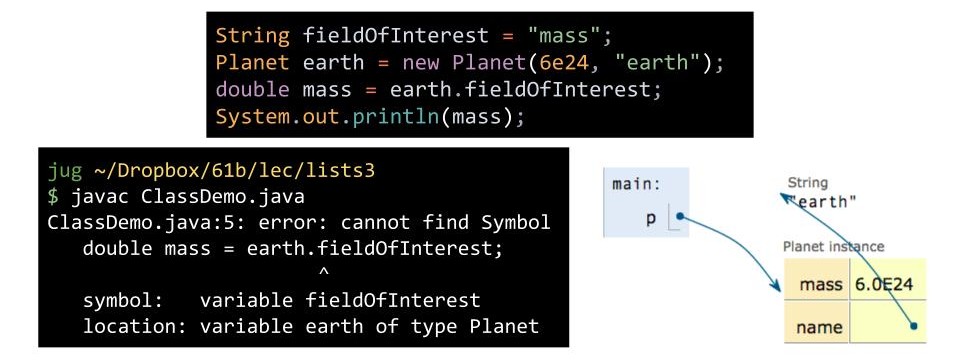
数组与类
数组和类都能被用来管理一些内存盒子。
- 数组使用
[]访问内部元素,而类使用.访问内部成员; - 数组元素的类型必须一致,而类的成员变量可以有不同的类型;
- 都有固定数量的内存盒子。
数组下标可以在程序运行时访问,而类的成员变量名不行。
数组列表(ArrayList,aka 动态数组)
之前我们已经实现过了循环链表,并且经过一系列优化,它的 addFirst、addLast、getFirst、getLast、removeFirst、removeLast 方法运行起来都很快。但为什么我们还需要数组列表呢?
如果我们需要从列表中间取任意一个节点,即使是我们的循环链表也需要从 sentinel.next 开始遍历。如果列表非常长,所花时间又多了起来。
而如果是数组,我们就可以利用数组下标直接定位到那个节点。这个操作是即时的,速度非常快。
但是之前我们提到过,数组的大小是固定的。所以我们不得不用数组来设计一个列表,这样只要内存没有耗尽 或是宇宙没有爆炸 我们就可以一直 addLast 下去。
让我们开始设计我们的 AList 吧!
简单的数组列表
public class AList { |
接着我们还要实现 removeLast 方法。在删除数组最后一元素时都有哪些变量需要得到改动?在此之前我们要明确一个基本事实:就像苹果新推出的 iOS26 产生了巨大的轰动,但用户并不在意液态玻璃效果的底层究竟是如何实现的,他们只关心液态玻璃效果是否真实,以及是否会与正常的交互产生冲突,这也正是我们要做的事情。我们要保证用户的实际体验与心里的预期一致。
/*删除列表最后一个元素*/ |
对于这个实现,有的同学可能会疑问:不对呀,你只更新了 size 变量,但最后一个元素的值你没有删除呀?事实上,用户访问最后一个元素都是通过 size 变量访问的。而 addLast 时,最后一个元素的值会直接被新值覆盖掉。所以即使不删除最后一个元素,在用户的感知上是没有区别的。
更新它的尺寸
目前我们已经实现了一个简单的数组列表:
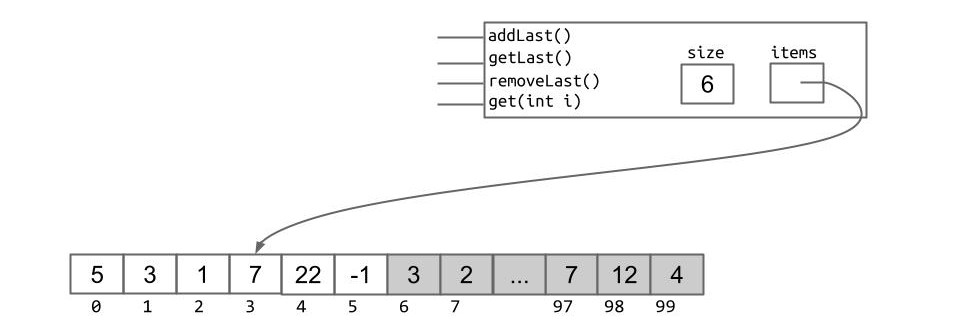
但我们还是不能调整它的尺寸。因此······我们要调整它的尺寸!但众所周知数组本身的尺寸是不能增加的,所以······我们就增加一个新的尺寸更大的数组!
/*调整当前数组尺寸到目标大小*/ |
问题是解决了,但是让我们想一下:如果我们已经填满了了一个容量为 100 的数组,而我们将不断 addLast 直到数组里面有 1000 个元素,我们将需要创建并填满多少个内存盒子?
没错,要 101 + 102 + ··· + 1000 ≈ 500000 个!
事实上,不只是空间,ALists 插入项目的用时相比 SLLists 还要长得多!
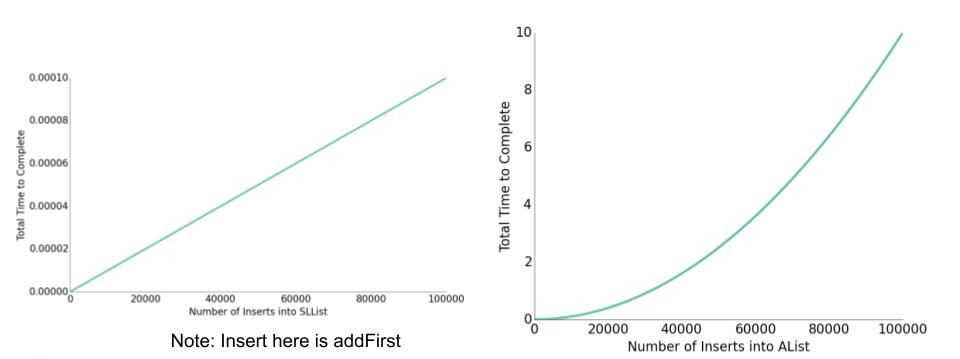
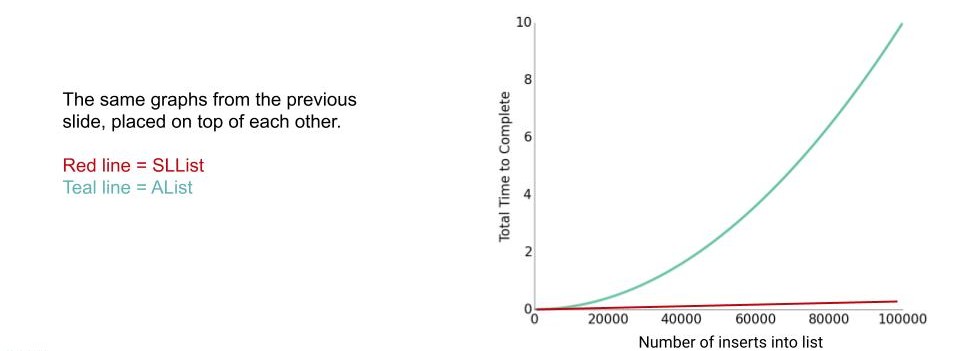
这完全与我们最初的意愿相悖以至于我们必须修正它。
可能有同学已经看出来了:我们每次数组扩容都只增加 1,这样扩容效率太低了。如果 resize(size + 10) 呢?对当下的情况确实有效!但当目标容量增加一个甚至几个数量级的时候用时又回到了老样子。
事实上,我们应该将扩容策略优化为“按倍数增长”,即:resize(size * 2),数组容量随扩容次数的增长便从之前的线性增长飞升为指数增长,扩容效率得到了显著提高。
更好的更新策略
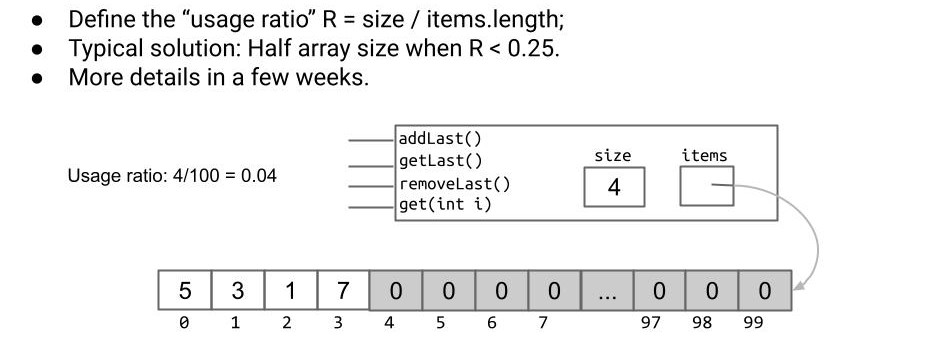
解决了扩容的问题,我们还剩下一个小问题:毕竟不同于链表的随用随扩随删随缩,元素数量与数据结构的尺寸完全一致,如果我们插入 1,000,000,000 个元素后删掉 990,000,000 个,我们将浪费 990,000,000 个内存盒子!所以我们还需要一个更好的缩容策略!
类似于扩容,我们的解决方法是创建一个较小的数组,将原数组的元素复制进去,然后丢弃较大的数组。具体的细节将在后面再进行讨论。
泛型
和之前的链表一样,我们的数组列表目前只支持整型,怎么让它支持更多的类型呢?像之前那样新增一个占位符 <Pineapple> 并然后把占位符当作新的类型用?对,但这次有点不太一样了因为 Java 有一个语法怪癖: 你不能实例化一个泛型类型的数组。
所以在实例化时,取代 items = new Pineapple[100],我们应该用 items = (Pineapple[]) new Object[100]。
最后一点,还记得之前我们在实现 removeLast 时使用的“little trick”吗?我们只是更新了 size 变量而没有删掉元素本身的值,一个关键原因是当时我们的数组元素的类型是 int,是基本类型之一,它的值直接存储在数组中并且添加新元素时会直接覆盖。
但当我们的数组元素是引用类型时,数组中存储的不是值,而是对值的引用,值用另外的一块内存存储。如果我们删除元素时不把这个引用断开,我们要删除的元素的值将永远在内存中不会被回收,直到 addLast 时修改了对这个值的引用。所以我们这次应该手动将其删除。
public Pineapple removeLast() { |
最终实现请查看: Project 1: Data Structures