列表(Lists)
整数列表(IntList)
public class IntList { |
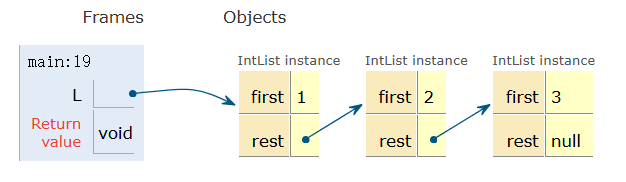
但这种列表未免有点丑,当我想列出 50 个这种东西那可够受的了。
于是我们尝试一下反向构建列表:
public class IntList { |
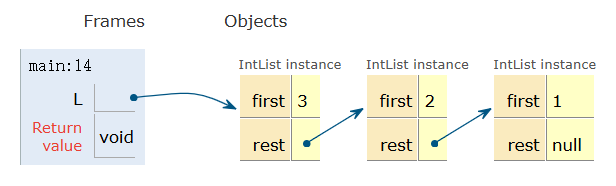
看起来整洁很多了,但如果拿来发布给全世界的人使用还是有些简陋了:如何弄清楚这个列表的大小?想取出第 10 个元素该怎么办?如何实现增、删、查、改?
所以我们还得添加几种方法来帮助用户使用这个列表。
/*递归返回列表的大小*/ |
单链表(SLList)
虽然实现了一些功能,但我们上一节实现的只是一个“裸递归”的数据结构,让我们尝试改进一下我们的列表,让我们的用户更容易使用。
我们先把前面所有的方法全部删掉,并进行一些便于理解的重命名:
public class IntNode { // IntList -> IntNode |
接着我们得在一个新类里面重新实现这些方法:
public class SLList { |
我们先来看一下和之前的区别吧!
如果用户想创建一个 IntList,他们必须写下:IntList X = new IntList(10, null); 这行代码,这意味着他们必须指定剩余列表的 null 值,必须对递归有着深刻的理解;
但是当他们想创建 SLList 时,只需要写下:IntList Y = new SLList(10); 就可以了,不必考虑正在进行的所有递归。
接着让我们尝试把 addFirst 和 getFirst 函数添加回来:
// 将元素 x 添加到列表头部 |
SLLists vs. IntLists

虽然从功能上讲,像 IntList 这样的“裸”链表(无封装递归结构)可以实现需求,但它非常难用。
- 使用 IntList 的人必须熟练掌握 Java 的引用机制,并具备递归思维。
- 相比之下,SLList(封装后的链表)的使用要简单得多——用户只需调用提供的方法即可。
- 那为什么不在 IntList 类中直接添加一个
addFirst方法呢?实际上,这样做是无法高效实现的。如果你尝试过就会发现,这不仅困难,而且效率低下。
语法补丁
方法已经实现好了,但如果淘气的用户既有一点 Java 基础,又懂一点递归,直接访问数据结构进行一些修改怎么办?例如:
SLList L = new SLList(15); |
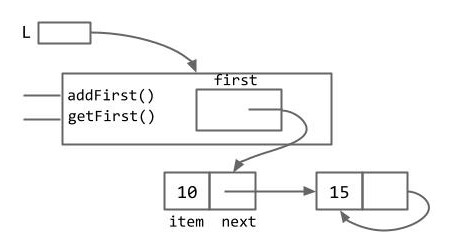
我们的列表就这样被毁掉了。那么我们该如何避免这种情况的发生呢?
权限控制

private 除了这个案例还有什么作用呢?
向类的使用者隐藏实现细节。
- 让类的使用者需要理解的内容更少;
- 私有方法(实现逻辑)的修改不会影响外部使用,更安全。
就比如对于一辆车:
public: 油门、刹车、方向盘······private: 喷油嘴、一些阀门······
如果开车时还要考虑 private 中的事情,这车可太难开了。
而如果你把车交给汽修工,他即使把油箱换成电池给你改了辆电车,只要没修坏,你也仍旧可以开因为油门刹车方向盘还在那里。
但即使如此,事实上,private 并不能算作是一个安全措施。因为只要用户有心,还是有途径获取到 private 内容的。
类的嵌套
显然除了 SLList 类,没有其他类会尝试使用 IntNode 这个类,所以我们还可以这样做:
public class SLList { |
作为 SLList 类的一个子功能而不是一个独立的类,这样看起来或许更有条理一些。
其他的方法
不止于 addFirst 和 getFirst,我们还可以实现一些其他方法:
// 在列表尾部添加元素 |
但在实现检查列表大小的方法 size() 时,你会发现问题:你无法再像 IntList 那样递归地返回列表大小了!
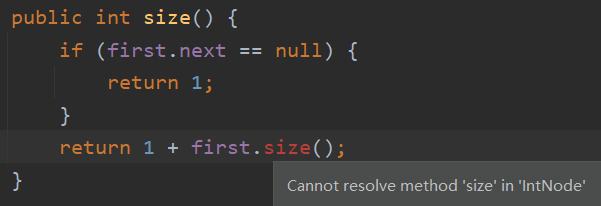
因为 SLList 不是一个递归的类,它里面没有类型为 SLList 的实例变量,我们就无法调用它自身来进行递归。因此我们得给它传入一个递归的类 IntNode,这样我们就可以通过 IntNode 的递归调用取得列表的大小。也就是将迭代后的 IntNode 变量作为参数再次传入函数中,直至 IntNode.next 为 null。
// 内部实现函数 |
但这样每一次我想查询列表的大小时都要递归遍历一次列表,列表元素多起来时耗费的时间将难以想象。如果对于每一次查询都能直接返回列表大小而不是查一次遍历一次该怎么做?
没错,只要为 SLList 类增加一个实例变量 private int size,每增加一个节点时 size += 1。至于 size() 方法,只要直接 return size 就可以了。然后删掉上面的方法
空列表
之前似乎只要初始化了列表,列表中就至少有 1 个元素。那么如何实现一个空列表呢?
// 只需要新增一个构造函数,该构造函数不接收任何参数 |
但其中有一个小 bug:如果你创建空列表后调用 addLast(),程序会报错。
bug
正如之前提到的: 你不能对 null 进行成员访问。 当头节点为 null 时,尝试对头节点进行成员访问时自然会报错。

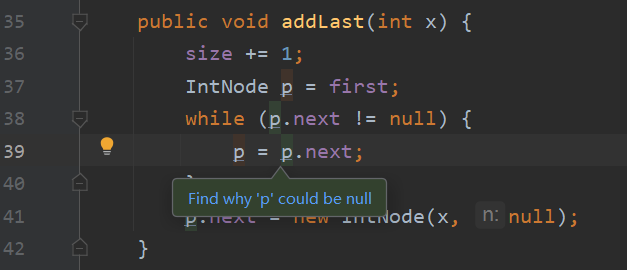
如何解决这个问题?很简单,只要为 addLast 添加一个头节点为空的特殊情况不就可以了吗?
public void addLast(int x) { |
问题是解决了,但这种解决方法似乎有点丑陋,因为这意味着对于所有会对头节点进行成员访问的方法,我们都要添加这个特殊情况。代码越复杂,解决起来就会越发丑陋且难以理解。有没有更优雅的解决方法?
哨兵节点
有的兄弟,有的!无论列表中有没有元素,我们都用一个不存储有效数据的头节点占位不就可以了吗?这个节点被称为“哨兵节点”或“虚拟节点”。
明确了思路,接下来只要进行一些便于理解的重命名和对方法的修改就可以了:
/*如果第一项存在,将作为 sentinel.next 存在*/ |
不变量
不变量(invariant) 是指在代码执行过程中必定为真的条件(假设代码本身没有错误)。
例如我们的 SLList 至少包含以下不变量:
sentinel引用始终指向哨兵节点;- 首节点(如果存在)始终位于
sentinel.next; size变量的值始终等于已添加元素的总数。
不变量让代码逻辑更易于推理:
- 可依赖不变量简化代码(例如
addLast方法无需处理null的情况); - 必须确保所有方法都维护这些不变量。
双链表(DLList)
然而我们上次实现的列表中仍存在一些问题:
- 每次在列表尾部添加节点的时候都需要遍历到最后一个节点,这样速度又有点慢。
这是个熟悉的问题,之前我们解决 size() 函数的时候就是为了节省遍历所需要的时间,而我们所做的就是增加了一个变量来存储列表的大小。那么如果我们增加一个“指针” last 来存储最后一个节点的引用呢?
- 对于
addLast()方法:我们只要找到last指针,增加节点last.next = new IntNode(x, null),更新last指针last = last.next就可以了; - 对于
getLast()方法:只要return last.item就可以了; - 但对于
removeLast()方法:删除了最后一个节点后还要更新last指针,这意味着我们要找到倒数第二个节点的引用。但我们又没有专门存储倒数第二个节点的引用的变量,所以我们仍然要遍历到倒数第二个节点,这样仍然很慢。
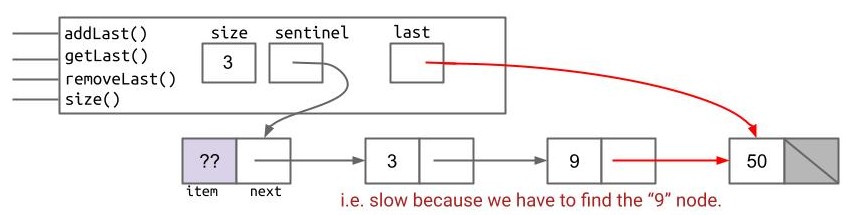
这个蹦出来的新问题又该如何解决?aha!如果每个节点不仅指向后面的节点,还指向它前面的节点,我就要找到倒数第二个节点就不需要遍历了!这样我们就得到了这样一个被称为“双链表”的结构:
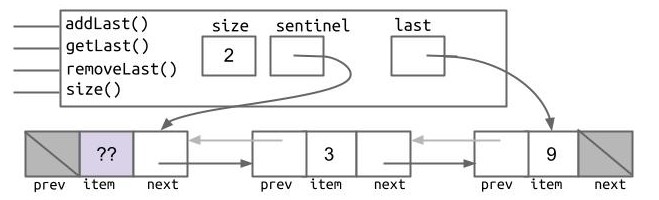
但这样处理仍然会有一个不怎么明显的问题。想象一下:如果这个列表是一个空列表,那么列表中只有一个 sentinel 节点,且 sentinel 的 prev 与 next 皆为 null。而此时我们的 last 指针指向 sentinel,当我们 removeLast() 时,会先移动 last 指针:last = last.prev 再 last.next = null,这样就再次出现了访问空指针的问题。
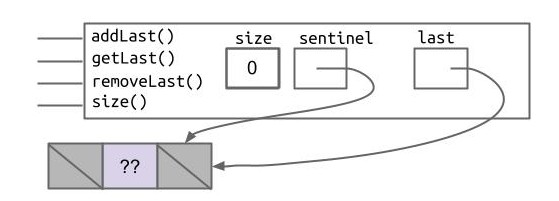
问题似乎又熟悉了起来。怎么办,像之前 addLast() 一样分情况讨论?不行,当初就否认了这种解法。
现在我们就有了两个选择:
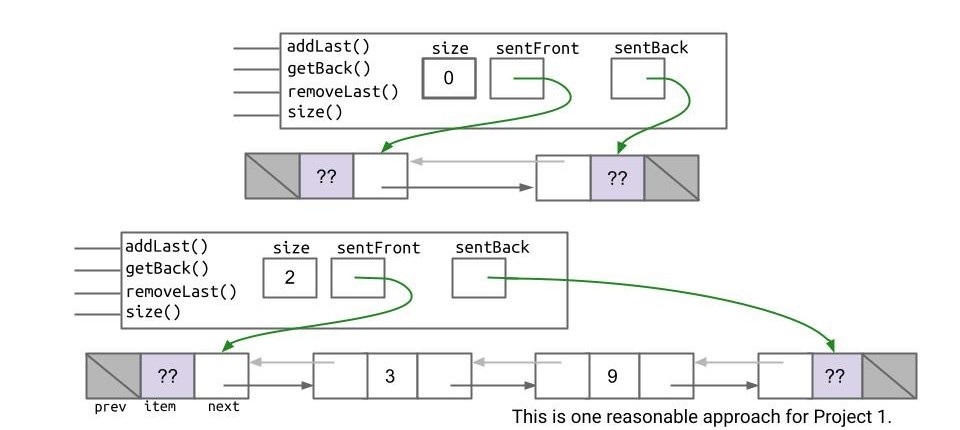
- 像当初一样,在末尾再加一个
sentinel:
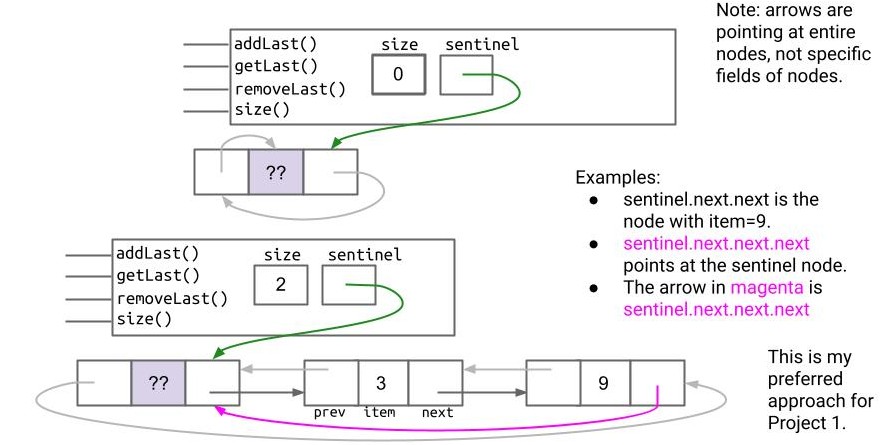
- 可能是构建双链表的最佳方式——循环链表:
到目前为止,我们取得了不错的进展!
但先别着急!目前我们还面临最后一个问题:我们的列表只支持整数类型,如果我们想拿来存储一些字符串,甚至是一些海象什么的怎么办?
可以把列表 item 的类型改成 String、Walrus 什么的,但这样我们同一个列表有了好几个副本,有点烦人。
事实上,Java 支持一种叫“泛型”的东西,允许用户临时决定变量的类型。
首先我们要给我们的类添加一个占位符,并把我们想要改变的类型用该占位符代替:
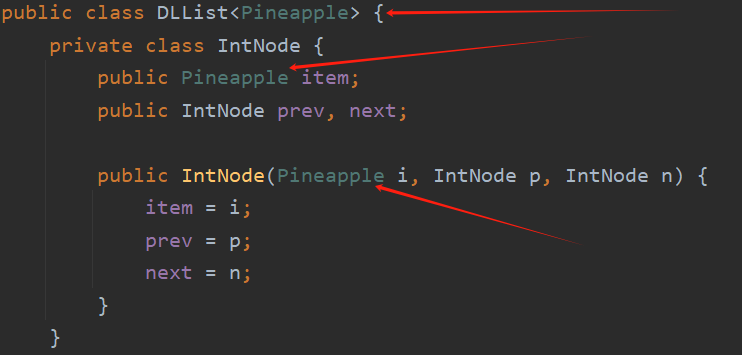
接着在我们创建列表的时候用我们想要的类型来替换占位符就可以了:
可以看作是一种高级的参数传递,Java 将取 String 并将每一个 Pineapple 实例替换为字符串,这样我们就有了支持字符串类型的列表。
- 那如何保证
sentinel的类型始终与提供的类型匹配呢?Java 中有 9 种类型,只要不是 8 种基本类型之一就是引用类型,null与任何引用类型兼容,因此设置为null即可。
最终实现请查看: Project 1: Data Structures


