树(Trees)
二叉搜索树(Binary Search Trees)
推导
我们现在有一个有序的链表:
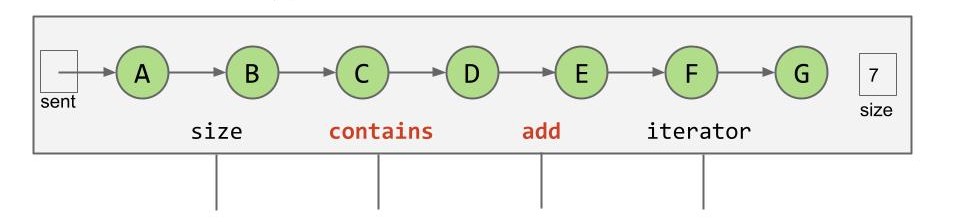
它有一个 sentinel,有 7 个存储有序键值(A-G)的节点,但它与常规的单链表没有什么区别。如果我们 contains(G) 或 add(H),它都需要遍历到最后才能完成查找和插入,用渐近分析的视角来看这是很慢的。我们有没有什么办法利用它的顺序性呢?
假如我将 sentinel 移到中间:

不过这样 A、B、C 节点我们就无法访问了,所以我们将 D 之前的指针反过来:

这样 D 之前的字母向左侧找,D 之后的字母向右侧找,我们便将搜索用时减半了!但我们还能不能做得更好?
让我们接着将这个思想应用在剩下的节点中:
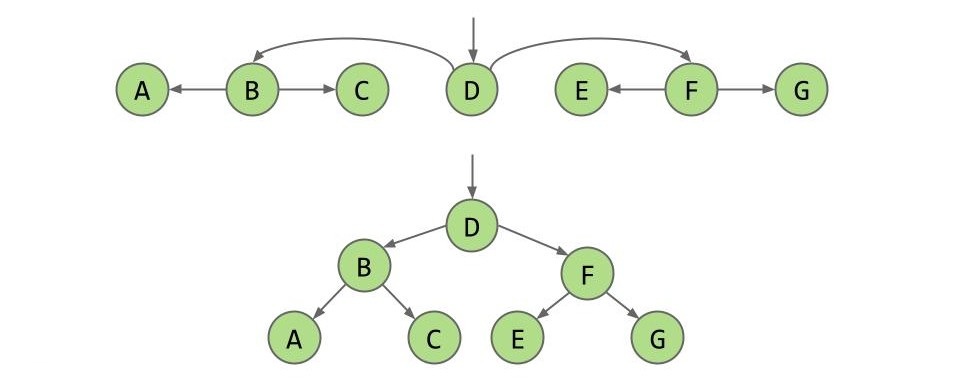
这样我们便得到了这样的一个树形结构。
定义
树是由一系列节点(Node)和一系列连接节点的边(Edge)组成的层次结构,要求:
- 从根到任意节点有唯一路径,无环(即不允许有回路)。
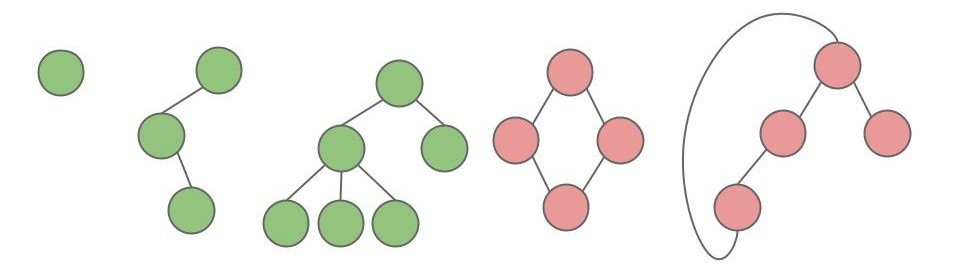
有根二叉树
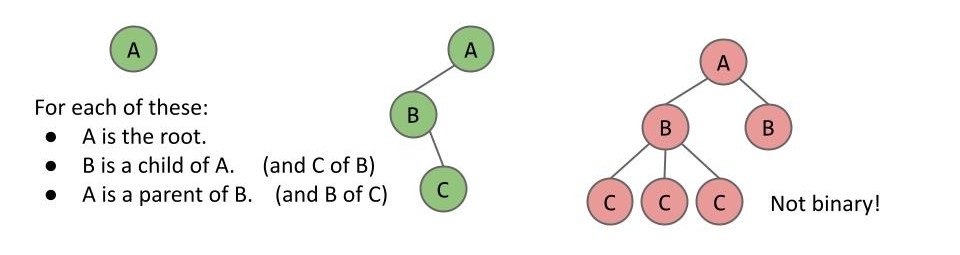
在一个有根树中,我们选择一个节点定义为根(Root)。
- 有且仅有一个根节点。
- 除根节点外,每个节点有且仅有一个父节点,被定义为从当前节点到根节点路径上的第一个节点。
- 没有子节点的节点被称为叶子节点(Leaf)。
- 一个有根的二叉树中每个节点只能有 0、1 或者 2 个子节点。
特殊类型:
- 满二叉树:所有非叶子节点都有 2 个子节点,且所有叶子在同一层。
- 完全二叉树:除最后一层外全满,最后一层从左向右填充。不难发现,满二叉树是一种特殊的完全二叉树。
二叉搜索树
二叉搜索树(Binary Search Trees) 是满足 BST 性质 的有根二叉树。(后面我将用 BST 指代二叉搜索树)
BST 性质:对树中任一节点X:
- 左子树所有节点的键 < X的键
- 右子树所有节点的键 > X的键
该顺序必须满足完全性、传递性和反对称性。对于任意两个键 和 :
- 和 中有且仅有一个成立;
- 如果 且 ,则必有 。
也因此,二叉搜索树中不允许存在重复的键值。
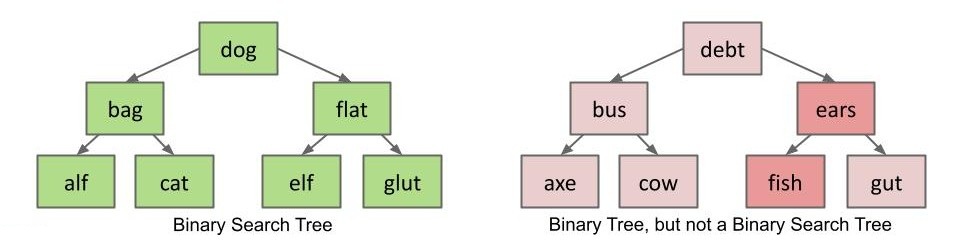
contains()
在 BST 中查找一个键的逻辑很简单:
- 如果
searchKey小于当前节点,搜索左子树; - 如果
searchKey大于当前节点,搜索右子树。
static BST contains(BST T, Key sk) { |
那么查找的速度怎么样呢?对于一棵有 N 个节点的 “茂密”(下一节会具体解释)的 BST,它的高度为 。查找时每层只会停留一次,所以速度应该是 。
add()
在 BST 中插入一个新节点的逻辑也很简单:
首先查找要插入的键:
- 如果找到了,什么都不做;
- 如果没找到,就创建一个新的节点并设置合适的连接。
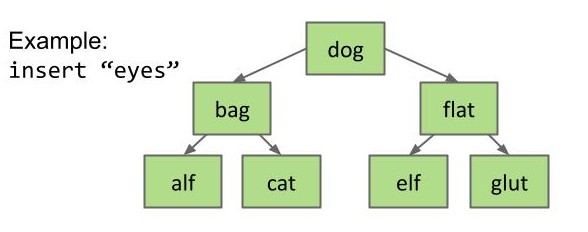
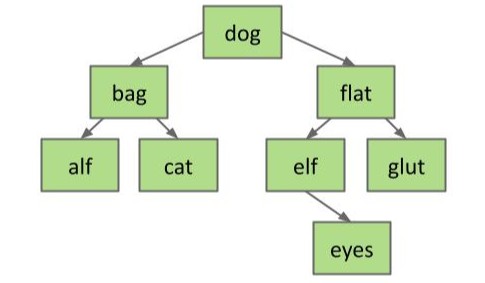
例如我们想向这棵树中插入一个新键值 eyes,就需要经历:eyes 比 dog 大,在 dog 的右子树中查找;eyes 比 flat 小,就在 flat 的左子树中查找;eyes 比 elf 大,就在 elf 的右子树中查找,但 elf 没有右子树了,所以创建一个存储 eyes 的新节点连接到 elf 的右子树上。
static BST add(BST T, Key ik) { |
值得一提的是,if (T == null) return new BST(ik); 并不能被换成:
if (T.left == null) |
因为后者并没有利用查找的逻辑递归到最后一层,会导致插入时产生错误。
希巴德删除(Hibbard deletion)
但删除节点时情况就复杂了,但我们倾向于将复杂情况拆分成几个简单的情况:
- 删除没有子节点的节点
- 删除一个子节点的节点
- 删除两个子节点的节点
case 1
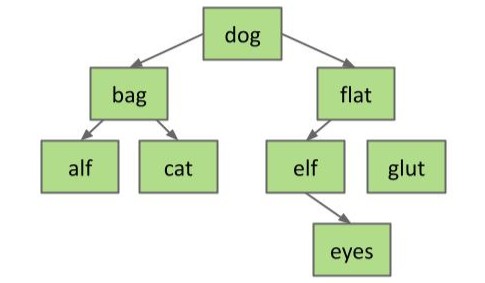
第一个情况最简单,假如我们想删除存储 glut 的节点,我们只需要将该节点与其父节点 flat 之间的连接断开,垃圾收集器会自动将该节点回收。
case 2
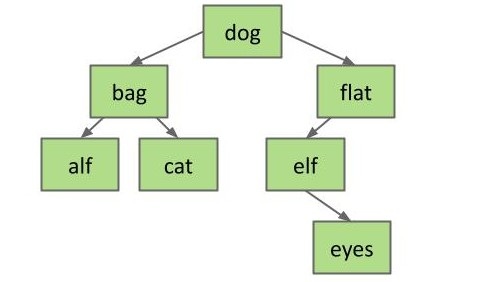
第二个情况会复杂一点,但也不算太糟。假如我们想删除存储 flat 的节点,如果我们还沿用上一个情况的方法直接切断该节点与父节点 dog 的连接,flat 节点的所有子节点也因此而消失了,这是不对的因为我们只想要删掉 flat 节点。
不过如果我们直接令 dog 节点原来指向 flat 节点的指针指向其子节点 elf。由于没有指针指向 flat节点了,该节点会直接被回收。而 flat 的子节点也一定比它的父节点 dog 大,将子节点接到父节点上后也没有破坏 BST 的逻辑,所以这样做是合理的。
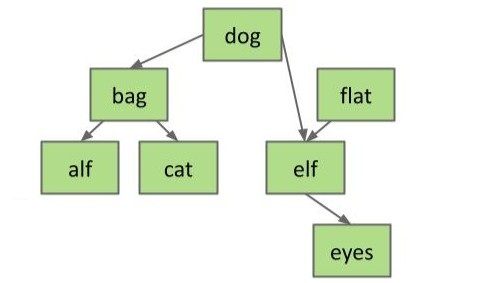
case 3
对于第三个情况我们就不得不变得聪明一点,不能简单地移动和删除了。假如我们想删除存储 dog 的节点该怎么办?
删除 dog 节点意味着我们的树没有根节点了,我们得找一个新的根节点满足:
- 该节点要大于左子树中的所有节点
- 该节点要小于右子树中的所有节点
哪个节点满足这两个条件呢?
我们得找到将 BST 还原成链表后 dog 节点的 前驱 或者 后继 节点,或者说左子树中最大的节点或右子树中最小的节点。

前驱(Predecessor):在某种遍历顺序中,排在当前节点之前的最近节点。
后继(Successor):在某种遍历顺序中,排在当前节点之后的最近节点。所以选择前驱/后继时:
- 前驱 = 左子树的最右节点
- 后继 = 右子树的最左节点
这些节点最多只有一个子节点(否则不可能是最左/最右),因此删除时只会触发 case 1/case 2
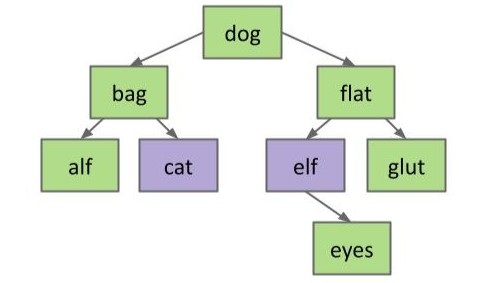
这棵树中,满足条件的节点有 cat 和 elf。找到了这两个节点就好办了!我们只需要从这两个节点中任选一个将键值复制到 dog 节点中,再将该节点删除就可以了。
B 树(B-Trees)
BST 的缺陷
我们之前提到过,对于一棵节点数为 N 的 BST,它的高度为 ,但前提是它得是“茂密的”。那到底什么是“茂密”?
对于一棵树:
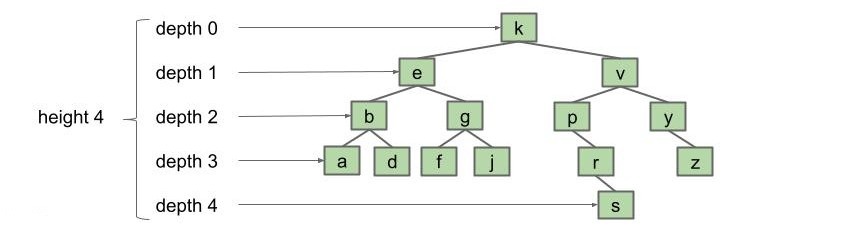
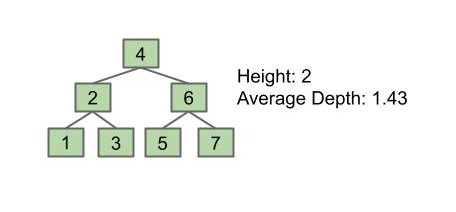
- 节点的 “深度” 是指 根到该节点的路径长度。如下面这棵树中
depth(g) = 2 - 树的 “高度” 是指 最深叶子节点的深度。如下面这棵树的高度
height(T) = depth(s) = 4 - “平均深度” 是指一棵树 所有节点的平均深度。如下面这棵树的平均深度为:
- 树的高度决定了查找一个节点的最坏情况的运行时间
- 平均深度决定了查找一个节点的平均情况的运行时间
平衡二叉树
平衡二叉树(Balanced Binary Tree)是一种结构平衡的二叉树,它的每个节点的左右两子树高度差都不超过 1。
平衡二叉树的高度为 ,所以我们所说的“茂密”指的就是 高度平衡。
| 平衡的树结构 | 不平衡的树结构 |
|---|---|
 |
 |
举个例子:同样要将 1、2、3、4、5、6、7 七个节点插入树中,
- 方法一:
add(1),add(2),add(3),add(4),add(5),add(6),add(7) - 方法二:
add(4),add(2),add(1),add(3),add(6),add(5),add(7)
| 方法一 | 方法二 |
|---|---|
 |
 |
显而易见,BST 最优情况就是方法二构造出的平衡的树,高度为 ;而最坏情况就是方法一构造出的“树棍”,高度为 。“树棍”就是不平衡的一个极端情况。
不过这只是我们理论上构造出来的 BST。实际上,我们只要随机地插入节点,构造出的 BST 就倾向于是平衡的。但现实不能总如我们所愿,如果我们要记录事件发生的时间,如:
add(“01-Jan-2019, 10:31:00”)
add(“01-Jan-2019, 18:51:00”)
add(“02-Jan-2019, 00:05:00”)
add(“02-Jan-2019, 23:10:00”)
插入的时间节点永远是递增的,我们最终必定会得到一根“树棍”,对其增删查改将无比痛苦。应该如何改进?
B-Trees
在二叉树中我们所说的的“键”到这里有了一个新名字:关键字。
关键字(Key)是指存储在节点中的用于比较和查找的数据单元。
BST 长成“树棍”的根本原因是:每次插入一个关键字时,总会创建一个新节点并挂到树的最底层,将树“堆”成了“树棍”。那如果我们无法在底部插入新节点,树不就不会被“堆”起来了吗?
为了避免插入,添加新关键字时我们不能创建新节点了,只能将新关键字“塞”到现有节点中去:
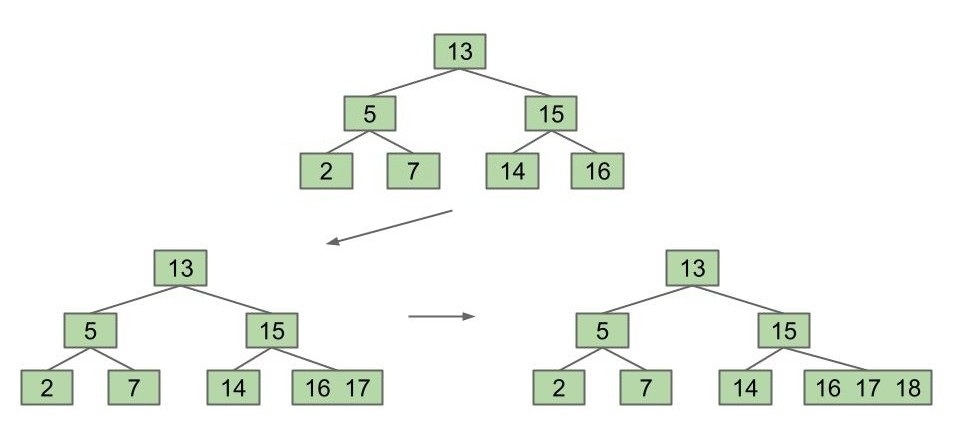
这样确实避免了我们的树被堆得越来越高,但也有个问题,随着添加的关键字越来越多,这个节点也将变得越来越“充盈”,最终效果与“树棍”没什么区别。应该如何接着改进?
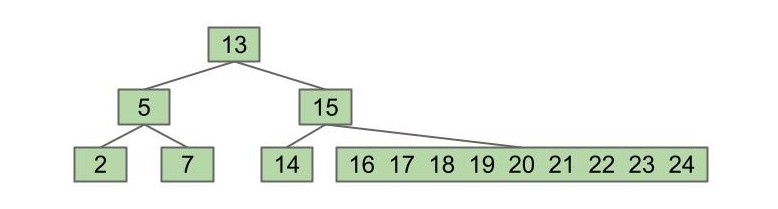
分裂“Juicy Nodes”
我们不妨给每个节点可容纳的关键字的数量设置一个限制 L,当节点中的关键字数量超过了限制 L 后,该节点将“撕”下来其中的一个关键字传递给父节点。假设这里我们的 L = 3,那具体“撕”下来哪一个关键字呢?我们先选择中间偏左的那个关键字:
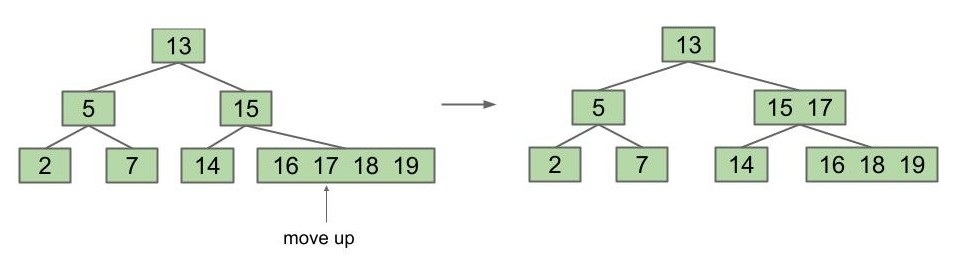
但现在还有一点我们不太喜欢:虽然 16 不比 17 大,但它仍然在右边的节点中,这显然违背了 BST 的性质。我们的解决方案是:17 被提升到父节点后,16 会随之与原节点分裂,成为一个独立的节点。
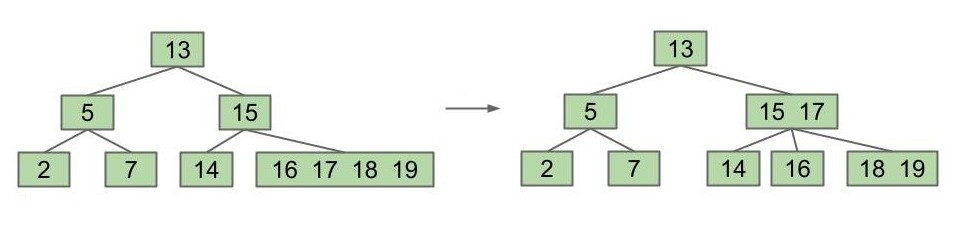
这样小于 15 的关键字都在左子树中;在 15 和 17 之间的关键字都在中间的子树中;大于 17 的关键字都在右子树中,看起来是非常合理的。值得一提的是,虽然在查找 19 的时候仍然需要遍历 18、19,但因为我们已经限制了节点内关键字的数量为常数,所以不必担心。
总结一下,添加新关键字时插入到现有节点中,现有节点太满时就提升一个关键字到上一级,提升一个关键字后现有节点也会分裂成两个新节点。这就是我们的“分裂树”的三个重要思想。
添加 20、21:
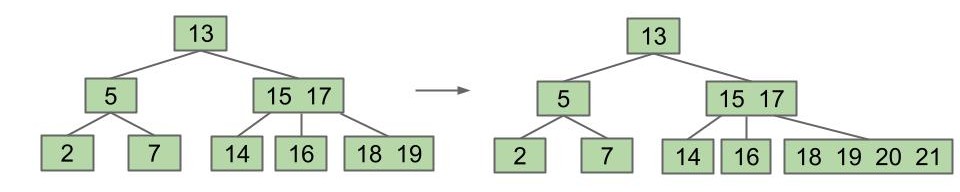
分裂:
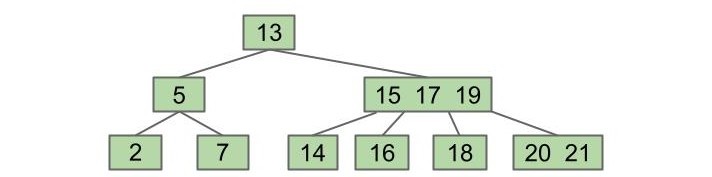
看起来非常的顺利且合理啊
分裂的链式反应
不过我们添加的关键字还是有点少,缺乏一般性。再添加一些关键字,上面的原理还适用吗?
让我们接着添加 25、26:
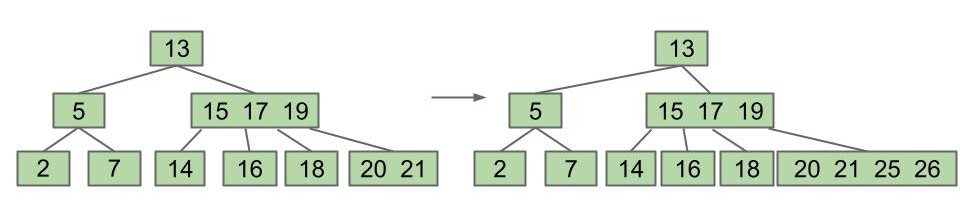
父节点也满了怎么办?利用同样的原理进行分裂!
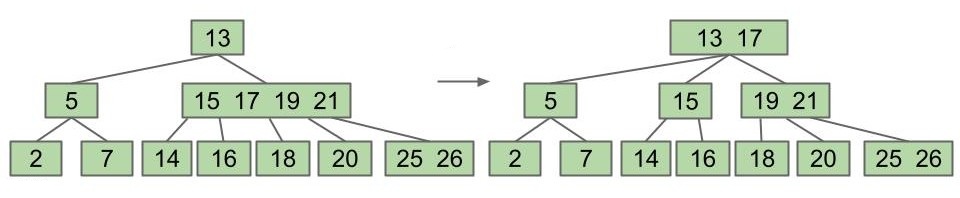
如果直到最后根节点也满了怎么办?也是同样的道理,只是这次没有了父节点,我们直接将被提升的关键字作为根节点就可以了:
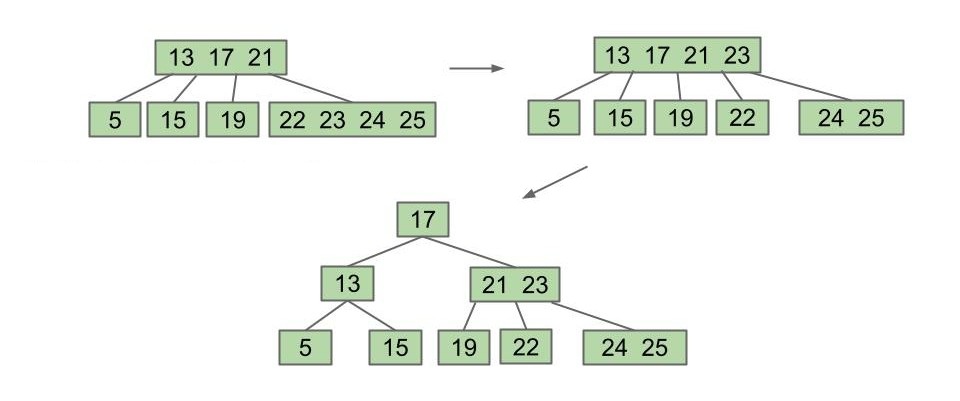
值得一提的是,根节点分裂后所有节点都被“推”下去了一层。
一些术语
显而易见,我们的“分裂树”在高度上有着完美的平衡。无论我们插入多少个关键字,它的高度只有在根节点分裂时才会增加 1,这样保证了树在分裂时一定是平衡的。且根节点分裂时每一个节点的高度都会增加 1,这样也就不可能出现“一枝独秀”的情况了。
不过遗憾的是这棵完美的“分裂树”并不是由我们发明的,所以我们不得不用它的“学名”:B 树(B-trees)。
- L = 2 的 B 树被称为 2-3 树
- L = 3 的 B 树被称为 2-3-4 树或 2-4 树
B 树在以下两种典型场景中最为常用:
- 小 L 值(L = 2 或 L = 3):作为能直观反映出概念的平衡搜索树使用(如现在)。
- 极大 L 值(如数千量级):实际应用于数据库和文件系统(即处理海量记录的系统)。
不变量
基于 B 树的构造原理,我们可以得到以下两个重要不变量:
- 所有叶子节点到根节点的距离一定相同。
- 包含 k 个关键字的非叶子节点一定恰好拥有 (k + 1) 个子节点。
这些不变量确保了 B 树始终保持平衡结构。
B 树的时间复杂度
又来到了我们每节喜闻乐见的保留节目——时间复杂度分析
同样的节点数,B 树理论上能达到最高的情况是每个非叶子节点内只包含 1 个关键字;而最矮的情况是,所有节点内的关键字数量都达到了上限 L。
我们以 L = 2 为例,最坏情况下我们只需要 7 个节点就能够使 B 树高度达到 2,此时高度的增长阶为 ;
而最优情况下我们共需要 26 个节点才能够使高度达到 2,此时高度的增长阶为 。
| 最坏情况 | 最优情况 |
|---|---|
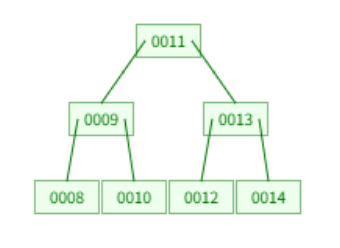 |
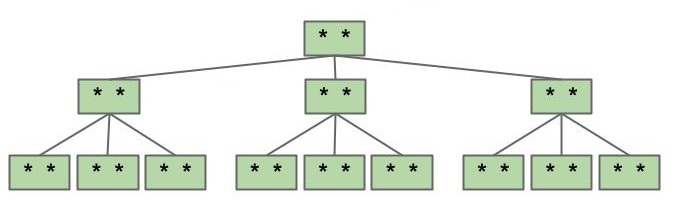 |
综合来看,B 树高度的增长阶就是 。
contains()
对于 contains(),最坏情况是从根节点开始,共遍历 H + 1 个节点,每个节点需遍历 L 个关键字,总运行时间为:。
又 ,L 为常数,那么总运行时间就是 。
add()
add() 会比 contains() 多一个分裂的步骤,就是当叶子节点内的关键字数量达到了 L,最坏情况下需要从叶子到根逐层分裂。每次调整的时间为 (移动内部关键字和指针),总调整次数为 H + 1,分裂需要的时间就是 。整体就是 。
delete()
删除操作不会被讨论,感兴趣的读者可以看看额外的幻灯片。但删除操作消耗的时间仍是 。
红黑树(Red-Black Trees)
好消息:B 树能完美地处理树的平衡问题。
坏消息:光读上面 B 树的内容就能感受到这玩意实现起来麻烦得要命。
下面是一部分伪代码:
public void put(Key key, Value val) { |
受 B 树的启发,我们能不能尝试做一点不同的事情?
树的旋转
假设我们有一个 BST,其中包括数字 1、2、3。基于上面我们学到的内容,根据我们添加这些数字的顺序,能够得到各种不同的 BST:

虽然树的结构不同,但这五棵树代表的都是一个包含数字 1、2、3 的集合,代表着同一棵树。既然如此,有没有一种方法能使一棵树在这些不同的形态之间切换呢?
结果是,有一个叫做 旋转 的操作可以让我们做到这一点。
左旋
rotateLeft(G):让 G 成为它的右子节点的左子节点。
什么意思?让我们先确定要操作的节点:G 和它的右子节点 P
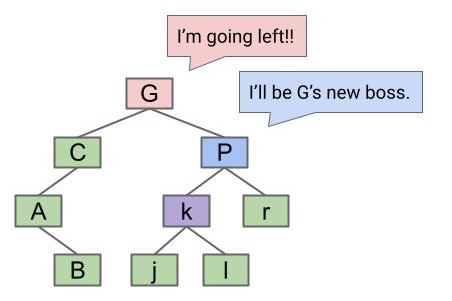
然后让 G 落下来,让 P 升上去:
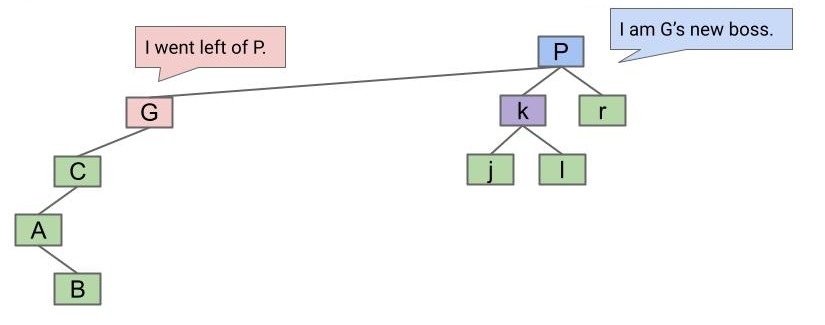
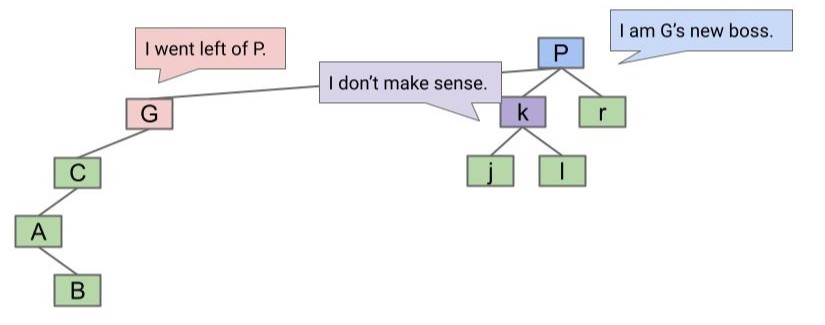
既然 k 比 G 大,又比 P 小,就让它成为 G 的右子节点吧:
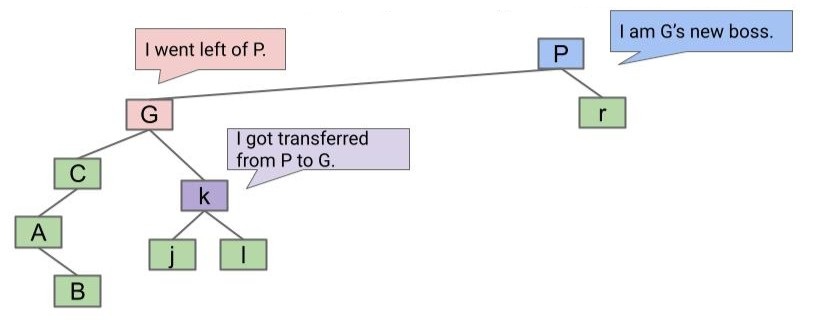
于是便得到了结果。
这个方法也许比较难懂,还可以这样理解:我们先把要操作的两个节点合并为一个节点,两个节点的子节点也都连接到这个合并的节点上,最后再进行子节点的分配。
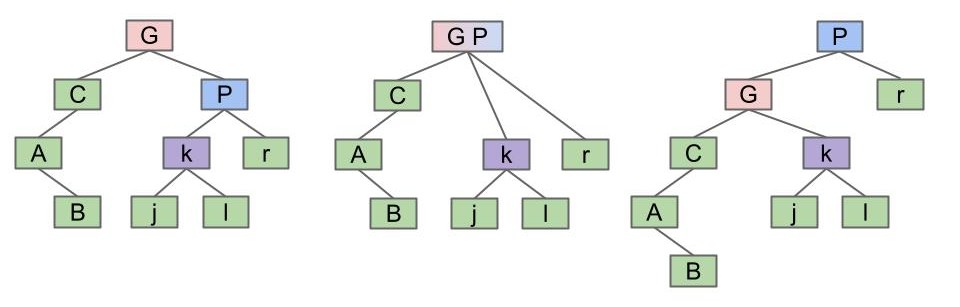
右旋
rotateRight(P):让 P 成为它的左子节点的右子节点。
方式与左旋同理。
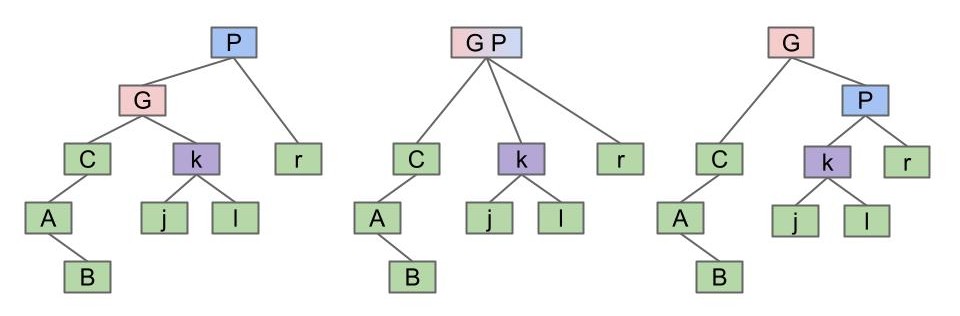
值得一提的是,尝试让没有左(右)子节点的节点进行右(左)旋的行为是未定义的,所幸在这个课程中你并不需要担心这一点。
旋转与平衡
事实证明:
- 旋转能够减少或增加一棵树的高度;
- 旋转仍然保持 BST 的性质。
所以我们可以通过一系列旋转来平衡一棵树:
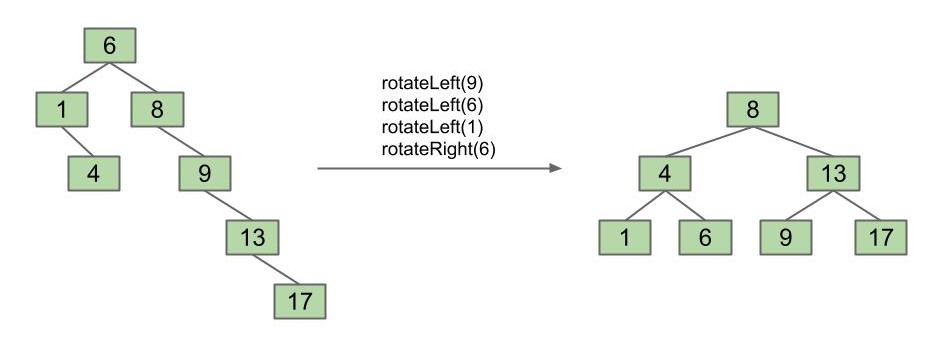
不过虽然从技术上来讲是可行的,但与我们即将学习的内容相比,我们并不倾向于这样做。因为我们将尝试利用旋转的概念来构建一个非常酷的东西,叫做 左倾红黑树(Left Leaning Red-Black Trees)。
左倾红黑树(Left Leaning Red-Black Trees)
目前我们已经学过了几种搜索树:
- 二叉搜索树:可以通过旋转进行平衡,但我们还不知道能做到的算法(目前)。
- 2-3 树:构建时保持平衡,不需要旋转。
既然我们希望 BST 也是平衡的,那我们能不能构建一种结构上与 2-3 树相同的 BST 呢?
每个节点只有一个关键字的 2-3 树结构与 BST 完全相同,很容易解决;但有两个关键字的怎么办?
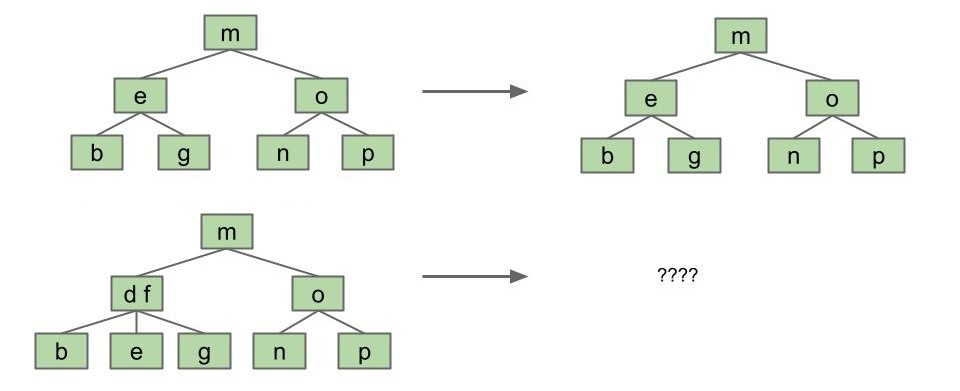
思路一:创建一个虚拟“胶水”节点
- “胶水”不存储有效的值,它只负责连接两个 2-3 树中的两个关键字。
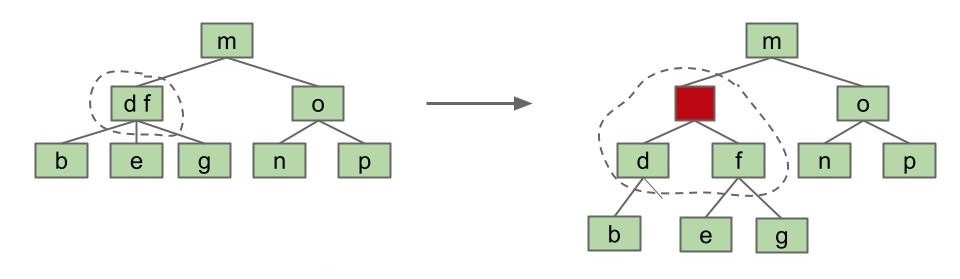
不过这种方法有点浪费:
- 首先我们不得不使用一个没有任何作用的节点,这意味着我们浪费了一个节点;
- 其次两个关键字节点将延伸出 4 个链接,但我们只用了其中的 3 个,这意味着我们又浪费了一个链接。
尽管这种方法概念上简单有效,我们并不倾向于这样做。
思路二:创建一个虚拟“胶水”链接
- 两个关键字中较小的一个将成为另一个的左子节点,二者通过“胶水”连接。
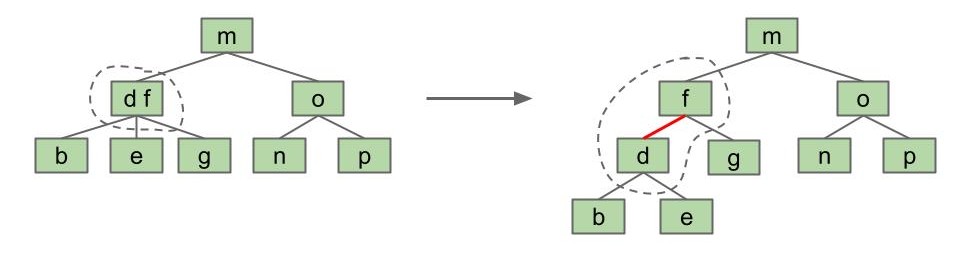
这种思路也是现实中普遍使用的实现思路。
为了便于理解,我们将这个虚拟链接标红:
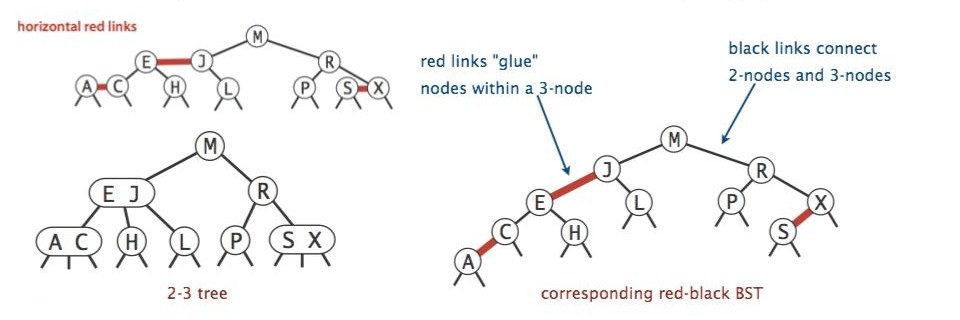
利用 左 胶合链接来表示 2-3 树的 BST 被称作 “左倾红黑树” 或 LLRB。
LLRB 的性质
接下来尝试画出下面这棵 2-3 树对应的 LLRB:
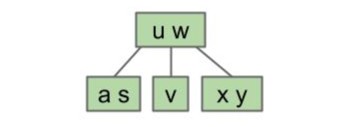
点击查看答案
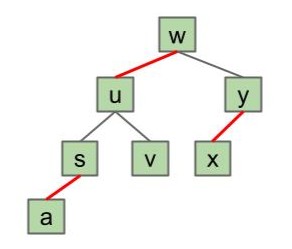
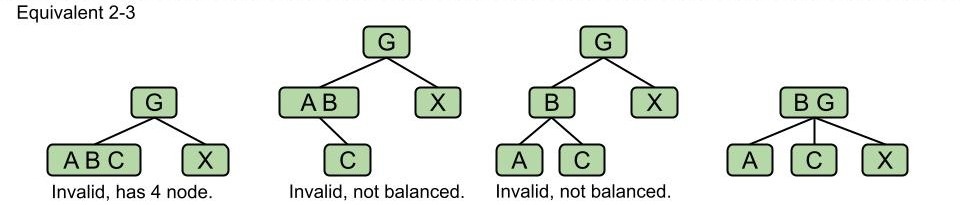
下面哪棵 LLRB 能够与一棵有效的 2-3 树对应?
点击查看答案
下面这棵 LLRB 对应的 2-3 树有多高?
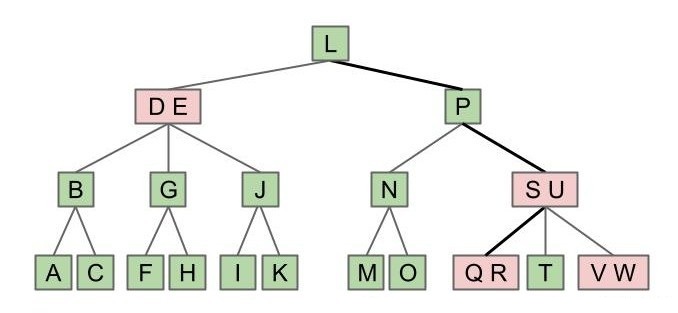
点击查看答案
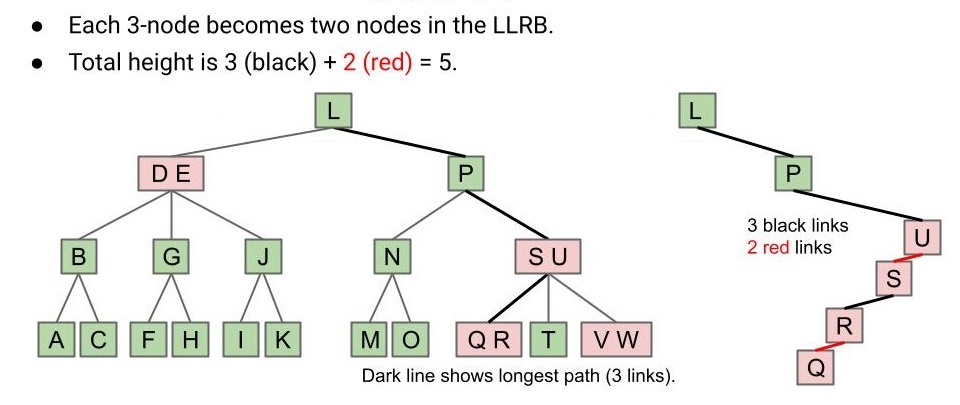
LLRB 的高度不会超过它对应的 2-3 树的高度的二倍,因此 LLRB 与 2-3 树同样有着对数级的高度。
LLRB 的构建
来到了最后一个也是最关键的问题:LLRB 是怎么来的?
先构建 2-3 树再转换成 LLRB?这这不能,因为 LLRB 就是来解决 2-3 树难以实现的问题;
事实上,我们要通过如下步骤,在插入节点时就实现 LLRB 的构建:
- 插入节点时与插入 BST 一致;
- 通过旋转来维持 LLRB 与 2-3 树的对应。
LLRB 就是基于不断维持这种一一对应的关系来实现的。让我们举几个例子:
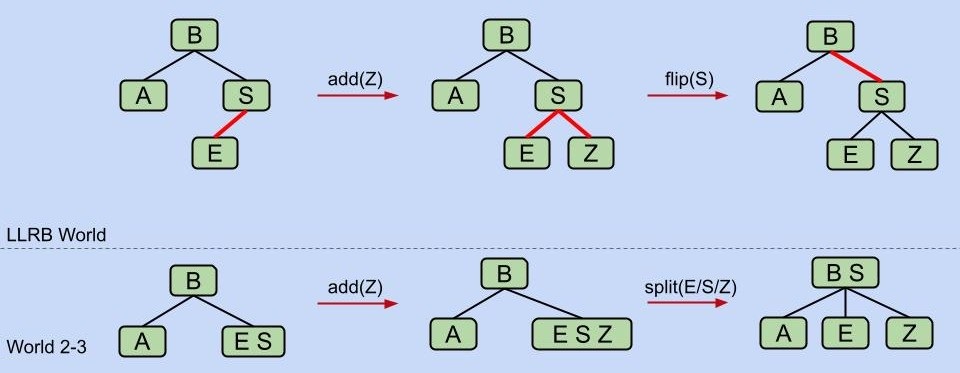
- 插入颜色
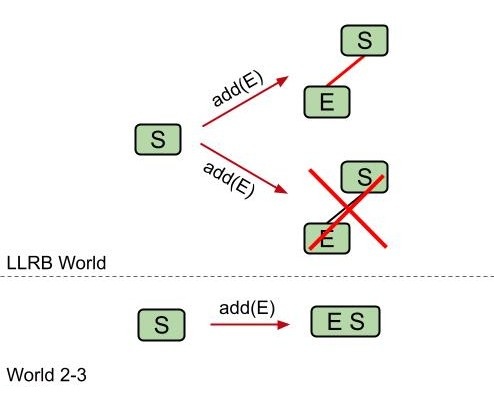
- 右节点插入
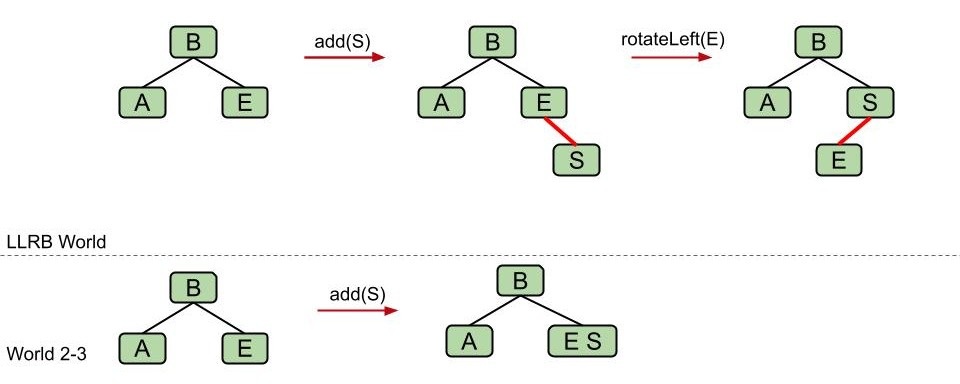
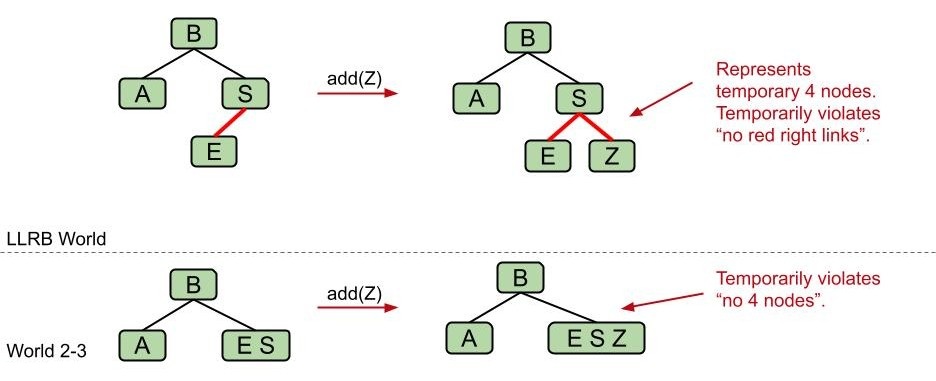
- 临时过度填充规则
我们将用两条红色链接来临时代表 2-3 树中 3 个关键字的节点。尽管这违背了“左倾”规则,但仅用来代表一个临时的状态是被允许的。
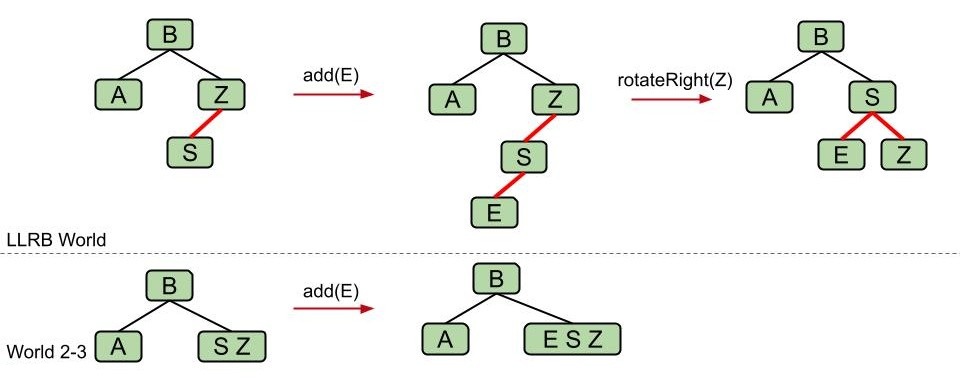
- 两次左节点插入
- 分裂节点
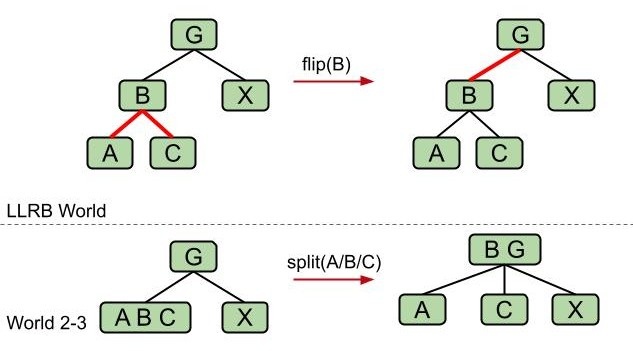
恭喜你!你现在发明了红黑 BST:
- 插入时,使用红色链接;
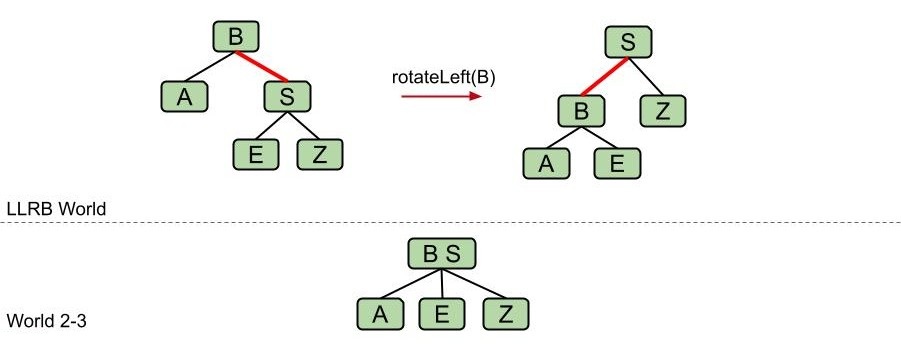
- 出现了右倾的节点时,左旋以进行修正;
- 左侧出现了两个连续的红色子链接时,右旋以进行修正;
- 出现了有两个红色子链接的节点时,将与该节点相连的所有边颜色反转。
当然,一次旋转或颜色反转可能会导致额外的违规情况需要修正。
Runtime
- LLRB 的高度为
contains()方法是add()方法是- 添加新节点时是
- 每次插入时的旋转和颜色反转是
总结
过去的 3 节,我们讨论了用于实现集合与映射的搜索树:
- 二叉搜索树:很普遍,但受制于不平衡
- B 树:平衡,但实现起来很痛苦且相对慢一点
- 左倾红黑树:很容易实现插入操作(但删除较难)
- 通过维持与 2-3 树的对应关系实现
- Java 的 TreeMap 就是红黑树(并非左倾)
- 与 2-3-4 树关联
- 两边都允许存在胶合链接(Red-Black Tree)
- 具有更复杂的实现,但明显更快
(大概
除此之外······
还有许多其它种类的搜索树
- 其它自平衡树:AVL 树、伸展树(Splay Tree)、树堆(Treap)······至少有上百种不同的树。
此外,还存在其他高效实现集合(sets)和映射(maps)的完整方案:
- 其它链式结构:跳表(Skip lists)——一种带有“快速通道”的链表(通过多级索引加速查询)。
- 完全不同的思路:哈希(Hashing)是最常见的替代方案,我们将在下一讲详细讨论这一重要概念。


