哈希表(Hash Tables)
这一节我认为 Josh Hug 讲得更清楚,所以这一节是基于 sp23 的。
PPT 链接
初识哈希表
哈希表的推导
ArrayOfListsSet
回到我们介绍 BST 时用到的基于单链表的列表:
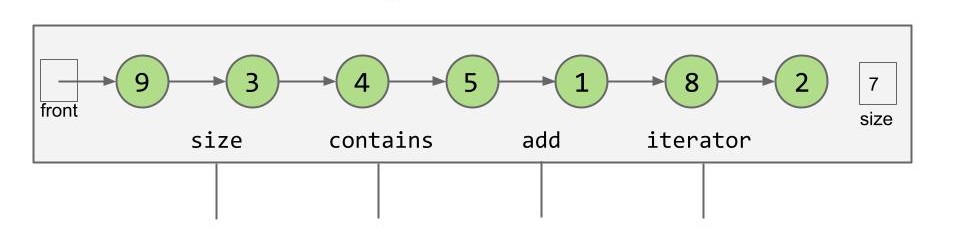
此时列表的 contains() 和 add() 方法显而易见是非常慢的。
引入 BST 时我们用到的方法是将列表排好序之后,将列表改造成一个树形结构。
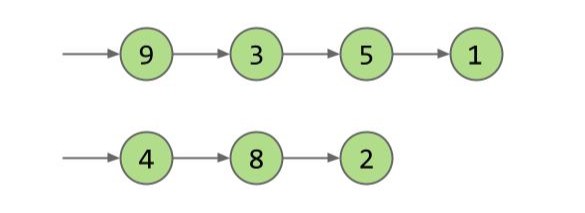
现在我们换一种思路:如果我们不进行排序,而是将我们的列表分裂成两个列表,一个存奇数,一个存偶数。如果元素被平均分配,那么 contains() 和 add() 的速度不就提高了二倍吗?
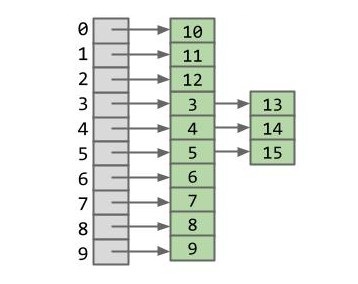
假如现在我们有了 10 个列表,对于 [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15] 这些元素又该如何分配?
没错,只要按照每个元素模 10 后的结果,也就是个位数字进行分配就可以了:
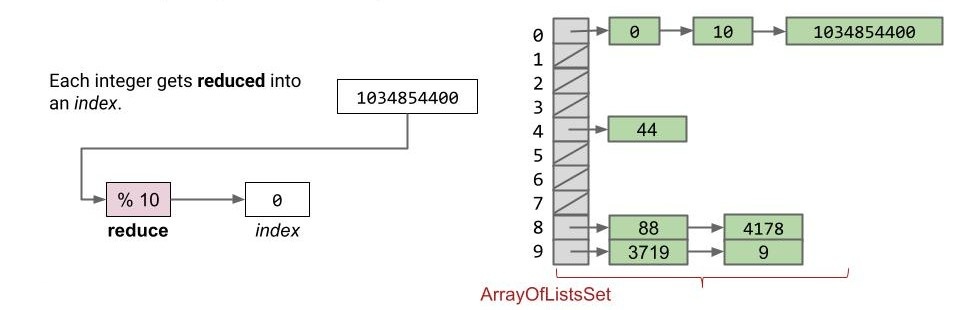
此时只要保证元素平均分配,我们的速度就提高了 10 倍!
下面是每个元素被分配时的流程。
如果我们一共有 N 个元素,平均分配到 M 个列表中,则每个列表的长度为 ,且最多可获得 M 倍的速度提升。
对于这种数据结构,每个列表通常被称作“桶(Bucket)”。
- 桶中的元素数量不定
- 元素在桶中的分布取决于缩减函数(reduction function)
DynamicArrayOfListsSet
不妨让我们的想法更疯狂一些:如果有多少整数(听起来有点怪)我们就有多少个桶,那每个操作岂不是都是 级的速度了吗?
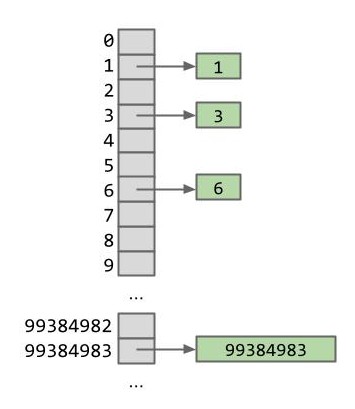
显而易见,这是一种极其浪费的方法。
- Java 能表示的整型并非无限,最小的整数是 -2147483648 而最大的整数是 2147483647
- 这意味着我们不仅需要一个尺寸有 40 多亿的数组,还需要 40 多亿个桶
我们能不能在运行时间于内存占用之间做出一些取舍呢?
我们起初将取一个较小的 M 值,随后 M 会随着 N 的增加而增大,类似于我们的动态数组(AList,ArrayDeque)。
现在我们指定一个规则:规定 为负载因数,当 时,。
如下图,当我们经过了 add(7), add(16), add(3), add(11), add(20), add(13) 后就需要进行一次 resize():
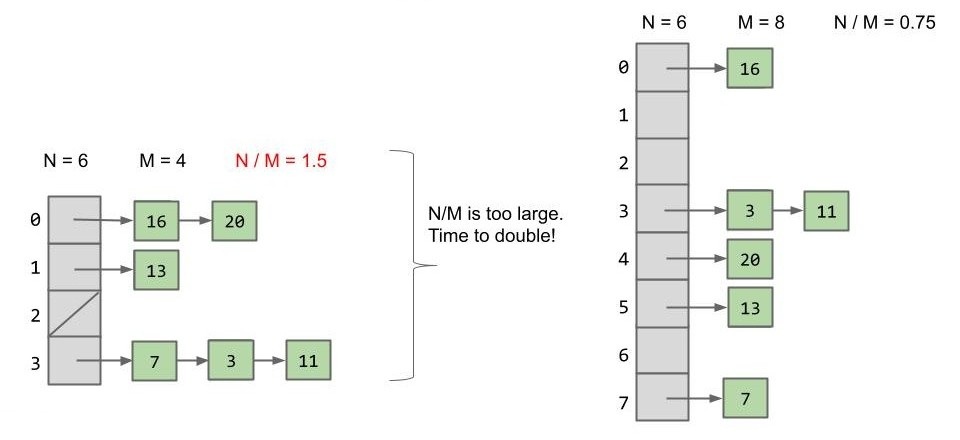
现在我们的这个数据结构就叫 “DynamicArrayOfListsSet”,与之前一样,只是 M 会随着 N 的增加而增大。如果 N 个元素被平均分配,每个桶的长度大小 。
- 最小时没有元素等于 0,最大能取到 1.5 渐近分析就是常数。所以每个操作的花费平均下来也是常数,显然要比那一堆树要快。
小写字符串
目前我们的数据结构用来存储整数十分合适,接下来让我们看看如何存储字符串吧:
假如我们想要 add("cat"),一个分配方案是按照首字母与桶编号进行匹配,如:
- a = 1, b = 2, c = 3, ···, z = 26
- 则 “cat” 会进入 3 号桶
这个方案的缺点也显而易见:
- 可以进行
resize,但实际派上用场的永远只有前 26 个桶 - 无法存储 “=98yae98fwyawef” 这种东西
我们得换种思路。假如我们将字符串视作一个 26 进制的数字:
- 仍然 a = 1, b = 2, c = 3, ···, z = 26
- 但 “cat” 对应的十进制数为:
只要我们的底数大于等于 26,就能保证每个小写英语单词都对应一个独一无二的十进制整数!
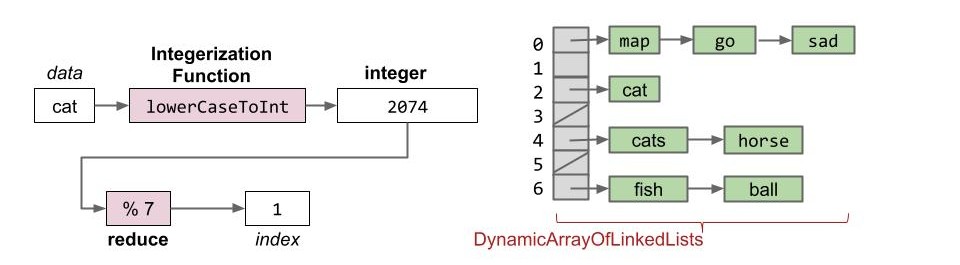
现在我们就能够处理字符串了:
- 数据首先经由一个整数化函数转换为整数
- 这个整数再经由缩减函数转换为一个有效的下标插入到对应桶中
整数溢出
但只对小写英语字母有效未免太严格了,如果我们想存储 “2pac” 或 “eGg!” 该怎么办?
像 26 个字母一样,我们就需要为每一个可能出现的字符分配一个数字匹配。听起来很累,但值得庆幸的是这件事已经有人做过了:
现在大多数计算机使用的最基本的字符集是 ASCII 格式。
- 每个可能的字符都被分配一个介于 0 到 127 之间的值
- 其中 33 - 126 是“可打印的”,如下图所示
char c = 'D'等价于char c = 68
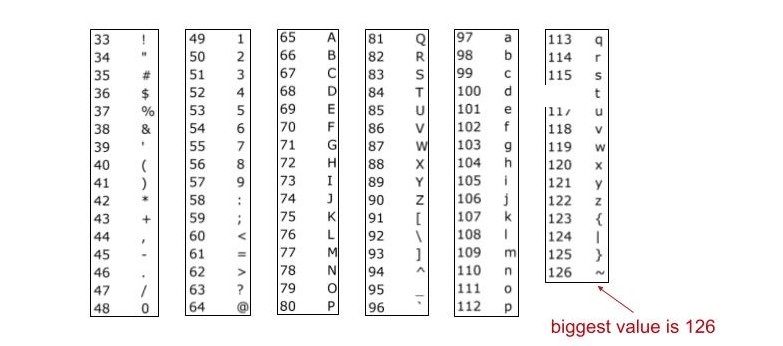
对于纯英文的文本包含标点符号最大的值为 126,那么就可以以 126 作为底数来保证我们的字符串有唯一的整数与其对应。如:
下面是一段将字符串转换为整数的程序:
public static int asciiToInt(String s) { |
如果想用 ASCII 之外的字符该怎么办?
Java 中的 char 类型也支持其它语言和符号的字符集:
char c = '☂'等价于char c = 9730char c = '鳌'等价于char c = 4014char c = '혜'等价于char c = 5481
这种编码方式被称为 Unicode。其对应表过于庞大,无法在此一一列举。
而中文字符的最大可能值为 40,959,因此如果我们需要为所有可能的中文字符串建立唯一表示,就必须以该值作为底数。如:
目前为止,我们一直在尝试将任何可能出现的字符串映射到一个唯一的整数。但前面我们也提到过,在 Java 中,最大的整数就是 2,147,483,647。如果你超过了这个界限,你就整数溢出了,计数将从最小的整数 -2,147,483,648 开始了。换句话说,2,147,483,647 的下一个数是 -2,147,483,648 而不是 2,147,483,648。
所以即使是以 126 为底数的英文字符串,也会导致整型溢出,更别提中文字符了。
- 这个值比 Java 的最大整数大多了,运行
asciiToInt("omens")的结果是 -1,867,853,901。
哈希码
由于 Java 的整数是有限的,我们这个“每个字符串都对应一个独一无二的整数”的集合最大就只能有 40 多亿个元素。
而我们一直在计算的这个数的正式术语称为 哈希码(hash code)。
根据 Wolfram Alpha 的定义:哈希函数(hash function)是一个“将一个具有大量(甚至无限)元素的集合中的值,映射到一个具有固定(较少)数量元素的集合中的值”的函数。
在这里,我们是将无限大的字符串集合映射到 Java 的整型数集合,其大小为 4,294,967,296。
也就是说,我们的整型化函数之所以被称为“哈希码”,是因为我们映射到的目标集合是固定大小的。而由于哈希码的取值范围是有限的,因此不可能为每个字符串都实现唯一的哈希编码。所以 Java 没有为了保证唯一性将 40,959 作为底数,而是使用 31。
- 尝试运行
System.out.println("守门员".hashCode());你会得到结果的。
当然无限的字符串集中也会有其它字符串同样映射到这个值,如:
- 682,923,529,464 整数溢出后的值就是 23,729,400。
哈希表
现在我们终于得到了哈希表(hash table)。
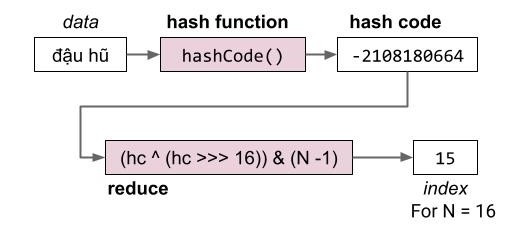
- 数据通过 哈希函数 转换为称为 哈希码 的整数表示,其取值范围为 -2,147,483,648 到 2,147,483,647。
- 哈希码随后会被缩减函数规约为一个有效索引,通常通过求模实现,例如:2348762878 % 10 = 8。
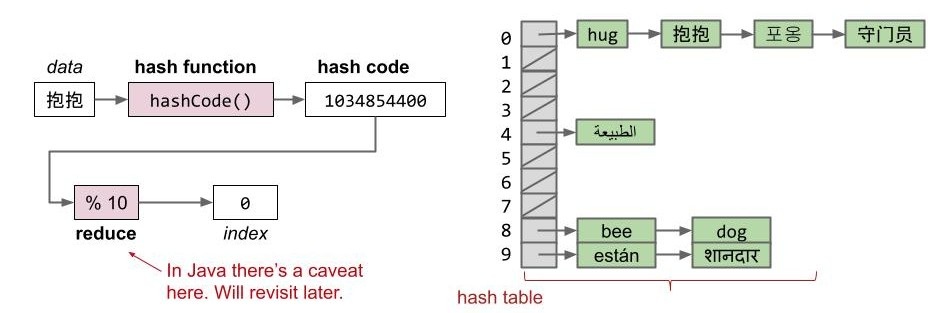
需要注意的是,哈希表存在多种实现方式。
我们当前使用的是由链表构成的数组结构(array of lists),这种方式有时被称为"分离链表法"(separate chaining)——其中每个桶(bucket)都是一个独立的元素链。
此外还存在更多复杂实现方案(如线性探测法、布谷鸟哈希法、使用非链表结构作为桶等)。
Java 中的哈希表
事实上,哈希表是集合和映射最常用的实现方式。
- 它在实际应用中性能出色
- 不要求元素实现 Comparable
- 实现起来相对简单
- Python 的字典(dictionary)本质上就是哈希表
在 Java 中,哈希表通过 java.util.HashMap 和 java.util.HashSet 实现。而 HashMap 又是如何计算每个对象的哈希码呢?
- 好消息是:Java并不需要
implements Hashable - 实际上,还记得我们在介绍 Object 类时提到的所有对象从 Object 继承的方法吗?Java 中的所有对象都必须实现
.hashCode()方法。
负哈希码
既然哈希码最小能够取到 -2,147,483,648,如果哈希码为负,又该如何取到它的有效索引呢?
假设  的哈希码是 -1,应放在
的哈希码是 -1,应放在 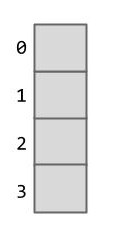 的哪个格子中呢?
的哪个格子中呢?
- -1 % 4 = -1,将会导致索引错误,所以通常利用
Math.floorMod进行计算。不妨尝试运行下面一段程序:
public class ModTest { |
所以我们的缩减函数也应使用 Math.floorMod 而不是简单的求模运算。
哈希表的性能表现与总结
对于无法 resize 的哈希表:
- 桶的数量恒为 M,元素数量 N 不断递增
- 若将每个元素平均分配,则每个桶中元素数量为
- ,则每次操作的运行时间 。
对于可 resize 的哈希表:
- 桶的数量 M 随着元素数量 N 的递增而递增
- 若将每个元素平均分配,则每个桶中元素数量为
- ,则每次操作的运行时间 。
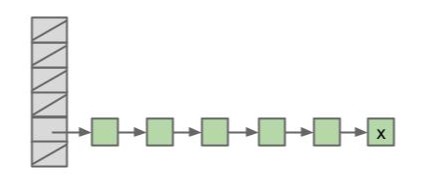
以上两种情况的前提都是元素的均匀分配。哈希表中元素的均匀分布对性能至关重要。 下面两种哈希表的负载因数都为 1,但显然右边的哈希表要优于左边的:
 |
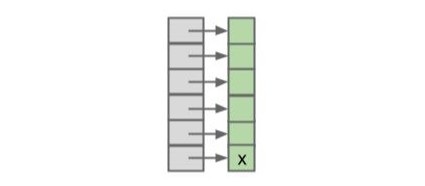 |
|---|
总结一下:
- 数据首先被转换成哈希码
- 接着哈希码会被缩减为有效索引
- 数据会根据有效索引被存储到一个桶中
- 当负载因数 达到某个常数时进行 resize
- 如果所有元素都被平均分配到每一个桶中,则每次操作的平均用时为
再探哈希表
对哈希表有了初步的理解,接下来让我们进一步理解:
- 哈希码如何影响元素的分配?
equals()与hashCode()之间有何联系?- 为何哈希表即使底层使用链表,运行速度仍然很快?
元素的分配
已经厌倦了字符串的我们现在打算向哈希表中插入名为 ColoredNumber 的对象,每个对象包含两个属性:数字的值 private int num 和数字的颜色 private Color color。当我们将 ColoredNumbers 0 到 19 插入一个带有 6 个桶的哈希表中,将会发生什么?

对于这些元素的分配,你注意到了什么?
- 十分随机,无逻辑可寻,且相对平均
- 有的行是其它行的二倍
- 奇数编号的行比偶数编号的长
- 数字 19 为什么会出现在第 0 行?
事实上 Java 默认的 hashCode() 实现(通常)直接使用 对象的内存地址 作为哈希值。例如:当你 new ColoredNumber(2) 时,返回的哈希码就是该对象在内存中的实际地址值。而将该哈希码对 6 取模后的结果恰好就是 0。
假如我们将 hashCode() 方法重写为只返回 0:
|
现在我们元素分配后的结果就变为了:

那如果我们想得到下面的分配结果,又该如何重写 hashCode() 方法?

点击查看答案
直接 return num 就可以了。
因此,我们可以将哈希函数定义为任何我们想要的样子。
hashCode() 与 equals()
为何需要自定义哈希函数?
哈希函数的目的是尽量让元素均匀分布。
- 您是完全不分散吗:return 0
- 欠佳的分散性:return 各位数字之和
- 良好的分散性:return num
那 hashCode() 默认按照内存地址分配的逻辑是好的吗?
其实是好的,内存地址实际上是随机的,因此元素也应该会均匀分布。
那既然 hashCode() 的默认实现能达到很好的分散性,为什么我们还需要费尽心思重新自定义一遍呢?
contains()
假如 ColoredNumber 类的 equals() 方法如下所示:
|
只要两个 ColoredNumber 的数值相等,它们就是相等的。
有了这个前提,现在我们向哈希表中添加 20 个元素:
int N = 20; |
接着查看 12 是否在哈希表中:
ColoredNumber twelve = new ColoredNumber(12); |
程序返回的结果应该是什么?
如果按照 equals() 的逻辑,两个 ColoredNumber 的数值相等它们就是相等的,程序应该返回 true。但事实是如此吗?
点击查看答案
事实上,程序返回 true 的概率为 而返回 false 的概率为 。
为什么会这样?
因为 hashCode() 是基于内存地址进行元素分配的,而开始时插入的 12 与查询时的 twelve 是分别 new 出来的两个对象,它们的 内存地址是不同的。因而 twelve 按照内存地址取模后分配到的桶与当初插入的 12 所在的桶相同的概率只有 。剩下 的概率目标对象和查询对象都不在同一个桶中,equals() 自然不可能返回 true。而 contains() 又依赖于 equals() 的返回值来判断目标值是否存在,结果显而易见。
所以换句话说:如果两个对象是相同的,那么它们应该拥有相同的哈希码,这样哈希表才能够找到它 ,这是最基本的原则。
现在回到上一节留下了的问题:
既然
hashCode()的默认实现能达到很好的分散性,为什么我们还需要费尽心思重新自定义一遍呢?
因为必须保持 equals() 和 hashCode() 的一致性,这是基础操作正常工作的必要条件。
重复值
假设我们的 equals() 方法不变,仍然不重写 hashCode():
public boolean equals(Object o) { |
ColoredNumber zero = new ColoredNumber(0); |
如果我们在下面的哈希表中调用 add(zero) 会发生什么?
- A. 0 号桶中会添加一个 0
- B. 1 号桶中会再添加一个 0
- C. 其它桶中会添加一个 0
- D. 同一个桶中不会出现重复的 0

点击查看答案
答案是 ACD
add() 的流程是根据 zero 的哈希值模 6 后的结果选择相应的桶,接着遍历该桶并不断检查 equals(zero)。如果返回 1 了就直接退出,如果一直遍历到最后了仍没退出就添加 zero。所以如果同一个桶中有了重复元素,equals() 会直接阻止添加;但如果重复元素没有出现在同一个桶中,equals() 就无能为力了。
所以综上,基于 如果两个对象是相同的,那么它们应该拥有相同的哈希码 的原则,
如果类重写了 equals() 方法,就必须以一致的方式重写 hashCode() 方法 。
否则将导致 HashSet/HashMap 等集合类出现不可预测的行为,这是 Java 对象契约中最关键的约束条件之一。
可变键值的风险
可变类型与不可变类型
不可变数据类型(immutable data type)是指一旦你实例化对象,它就无法以任何可观察的方式修改的数据类型。
public class Date { |
final 关键字可辅助编译器确保不可变性:
final变量仅允许一次赋值(在构造器或初始化器中),赋值后永不可修改final既不是实现类不可变的充分条件,也不是必要条件
下面这四个例子中,哪些是可变的哪些是不可变的?

显然,第一个是可变的,只要实例化一个 Pebble p 后直接 p.weight = 2; 就可以修改了。
第二个,我们刚刚介绍过,显然是不可变的。也许我们可以通过某些特殊的手段来修改,但正常来说就是不可变的。
第三个是可变的。
Rock r1 = new Rock(10); |
虽然 RocksBox 的内部字段 rocks 被声明为 final,但众所周知数组是引用类型,它的内存地址存储的是对数组对象的引用而不是数组本身。将其声明为 final 只意味着 rocks 对应的用于存储对象地址的 64 位内存无法改变,该地址指向的对象就无法被控制了。因此 rb.rocks[1] = null; 能够直接对数组进行修改。
第四个,即使我们将 rocks 声明为 private,这也是可变性非常微妙的原因之一,rocks 仍然是会受到某种类型的攻击:
Rock r1 = new Rock(10); |
我们在介绍引用类型时提到过,Java 是引用副本传递类型,因此 rox 和 rocks 是两个指向同一个副本的引用。即使 rocks 是私有的,那只意味着你无法通过 rocks 对对象进行修改而已。通过 rox 修改仍然会影响到 rocks 指向的对象。
解决方法也很简单:既然会产生这种影响是因为两个引用指向同一个对象,那么我让不可变的那个引用指向一个只属于它自己的对象不就好了吗?
public class SecretRocks { |
这样无论如何修改 rox 都不可能影响 rocks 了。
可变哈希键
为什么要介绍上面这些东西?事实上,我们可以创建一个 HashSet<List>,但如果:
- 向
HashSet中插入一个List - 接着修改那个
List
将发生一些奇怪的事情。
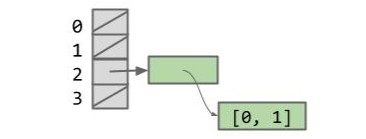
假如我们有一个 ArrayList items 为 [0, 1],该列表的哈希码为 962。
List<Integer> items = new ArrayList<>(); |
如果我们将该列表添加到一个有 4 个桶的 HashSet 中,它将被分配到 2 号桶(962 % 4 = 2)。
HashSet<List<Integer>> hs = new HashSet<>(); |
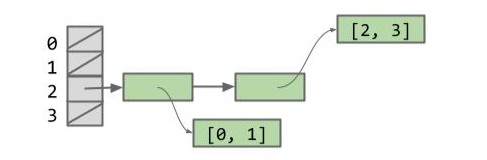
接着我们再添加一个列表 [2, 3],该列表的哈希码为 1026,也将被分配到 2 号桶。
hs.add(List.of(2, 3)); |
现在我们向 items 中添加一个数字 7,items 的哈希码将变为 29829,这会产生什么问题?
items.add(7); |
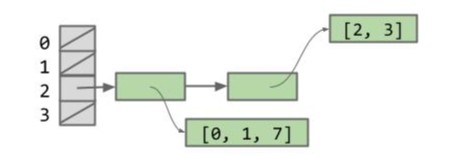
如果我们调用 contains(items):
- 29829 % 4 = 1
- 哈希表将检查 1 号桶并发现为空!
所以 永远不要修改一个被用作键的对象! 否则将导致数据检索错误和元素的丢失。这是因为添加时与查找时所依据的哈希码不同,导致违反 key.equals(key) == true 的基本契约。
附录
哈希表的一些基本契约
哈希码一致性(Hash Code Consistency)
- 若
a.equals(b) == true,则a.hashCode() == b.hashCode()- 两个逻辑相等的对象返回不同哈希码,会导致哈希表无法正确检索
等价性对称(Equivalence Symmetry)
a.equals(b)必须与b.equals(a)结果一致- 违反后果:可能造成哈希表重复存储逻辑相同的键
空键处理(Null Key Handling)
- 多数实现要求哈希表必须能处理
null键(如Java的HashMap)- 某些优化版哈希表(如Android的
ArrayMap)可能禁止null键
- 某些优化版哈希表(如Android的
哈希冲突处理(Collision Resolution)
- 即使
a.hashCode() == b.hashCode()但!a.equals(b),哈希表仍需正确存储这两个键- 实现方式:通过链表/红黑树(Java 8+的
HashMap)或开放寻址法处理冲突
- 实现方式:通过链表/红黑树(Java 8+的
时间复杂性保证(Time Complexity)
- 插入/查找/删除操作平均时间复杂度应为
不可变键推荐(Immutability Recommendation)
- 键对象应为不可变(如
String、Integer)- 若键对象被修改,会导致:
- 哈希码变化 → 无法通过
get()检索原值 - 内存泄漏 → 旧哈希桶中的条目成为"僵尸数据"
- 哈希码变化 → 无法通过
- 若键对象被修改,会导致:
负载因数约束(Load Factor Control)
- 当负载因数超过 时自动扩容并重新哈希
- Java
HashMap默认负载因数为 0.75
- Java
违反契约的典型后果
| 违反类型 | 可能结果 |
|---|---|
| 哈希码不一致 | HashSet.contains() 返回错误结果 |
| 可变键修改 | 数据"消失"(实际仍存在于错误桶中) |
| 非对称等价性 | 重复存储逻辑相同的键 |
Java 的 HashSet 实现
HashSet: https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/HashSet.java
HashMap: https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/HashMap.java
FAQ
哈希集合(Hash Set)、哈希映射(Hash Map)与哈希表(Hash Table)直接有何区别?
- 哈希集合是基于“哈希表”实现的集合抽象数据类型(Set ADT)。
- 哈希映射是基于“哈希表”实现的映射抽象数据类型(Map ADT)。
- 哈希表是一种存储信息的方式,其利用 M 个桶来存储 N 个元素。每个元素都有一个“hashCode”,用于确定应放入 M 个桶中的哪一个。


