堆与优先队列(Heaps & Priority Queues)
优先队列(Priority Queues)
什么是 优先队列?你可以将其想象成一个袋子,你可以把东西放进去,也可以把东西拿出来,也可以看看袋子里面有多少东西。听起来好像和其它数据结构没什么区别,但这个袋子的特殊之处在于它每次只允许你与最小的东西交互。有了这个约束,我们实际上会获得比其它复杂的数据结构更好的性能。
优先队列具有如下 API:
PQ 的使用
假设我们有一个粒子探测器,每天会记录一系列粒子的能量。而我们只想要一天中能量最高的 M 个粒子,我们该怎么做?
最容易想道的方法就是用一个列表将这一天所有粒子的能量信息都存储起来,用一个 Comparator 将其从大到小排好序,最后返回前 M 个元素。
这个方法听起来很有效,但问题是实际上它将使用非常多的内存。如果总粒子数为 N,则内存使用量为 。如果一天采集了一百万个粒子,而最终只取前 10 个能量最高的粒子,我们将浪费大量内存。
而要想要达到 的内存使用量,就需要用到我们今天的主角——优先队列(后面我将用“PQ”来指代)。
和列表一样,当探测到新粒子时,我们会将其丢到 PQ 中。但不同的是,当 PQ 中的粒子数量超过了 M 的时候,我们利用 PQ 的特性将能量最小的粒子弹出就可以了。这样无论一天采集了多少粒子,我们都只追踪前 M 个能量最大的粒子,因此节省了大量内存。
PQ 的实现
知道 PQ 怎么用了,但 PQ 该怎么实现呢?我们目前有几个选择:
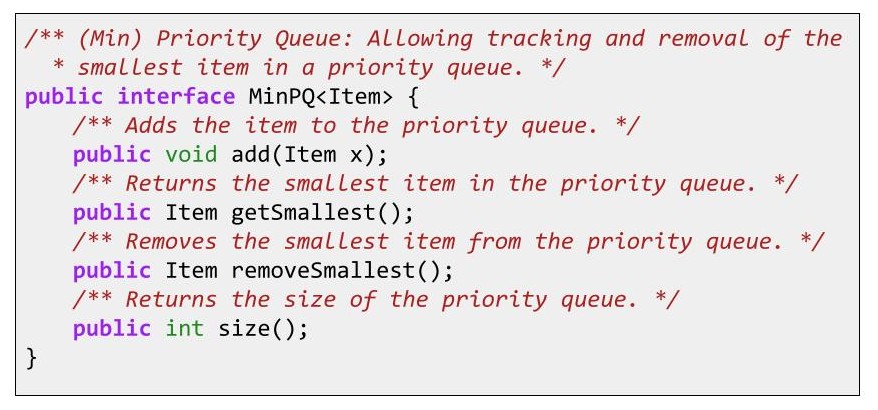
- 有序数组:有时需要遍历
- 平衡 BST:维持平衡比较恼人,处理重复项的优先级也很尴尬
- 哈希表:垃圾,内部元素是无序的,找到最小元素只能遍历
堆(Heaps)
堆的定义
在时间复杂度方面,上面的几个选择中只有 BST 表现得不错,但 BST 在保持平衡和处理重复项方面比较困难,于是我们有了:
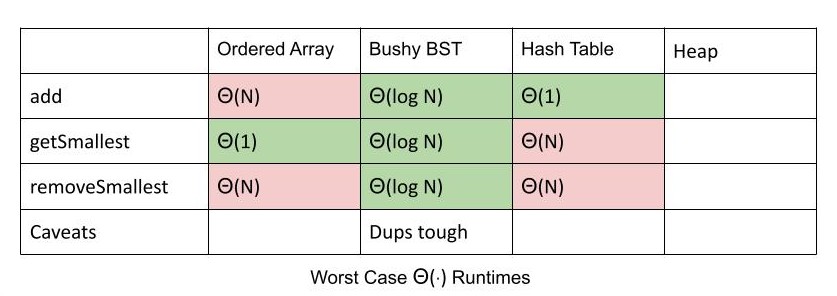
二叉最小堆(Binary min-heap):满足 最小堆性质 的 完全二叉树。
- 最小堆性质:每个节点的值 ≤ 其所有子节点的值
- 完全二叉树:空缺仅出现在最底层(若有),所有节点必须尽可能靠左排列
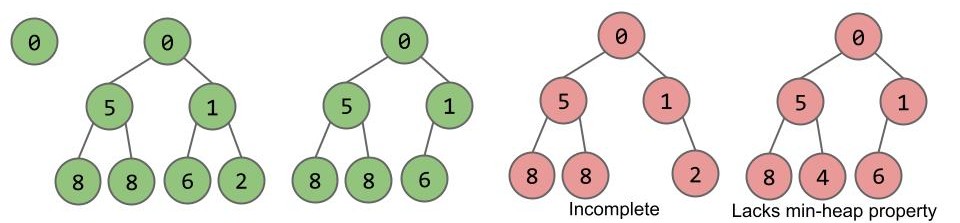
堆生来就是为实现 PQ 而服务的。那么如何实现 PQ 的 API?
先从最简单的开始,我们喜欢简单的东西。根据二叉最小堆的性质,堆的根节点一定是堆中的最小值。所以对于 getSmallest(),直接将根节点的值返回就可以了。
add()
如何向下面这个堆中插入一个节点 3?
要知道我们想要保证插入前后该数据结构相关操作的运行时间都很快,该数据结构就必须始终满足 完全二叉树的结构 与 最小堆的性质 这两个条件。如何做到呢?
既然同时满足两个条件地插入是十分困难的,我们不妨插入时暂且先满足一个条件,另一个条件通过后期修正来达成。
看起来最简单的事情,就是先确定新节点的位置!为了满足完全二叉树的结构,我们新插入的节点应该安插在最后一层的最左边:
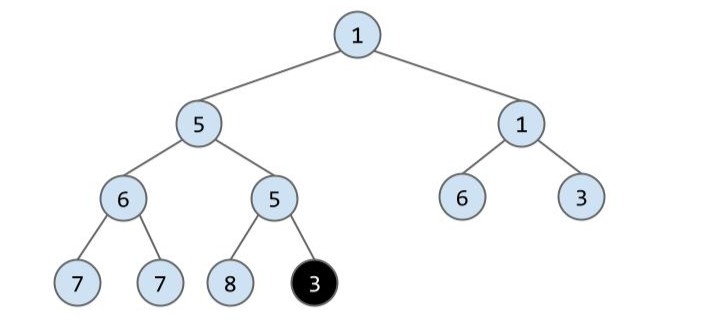
但是此时并不满足最小堆的性质,3 要比它父节点的值 5 小,所以我们将这两个节点交互一次位置:
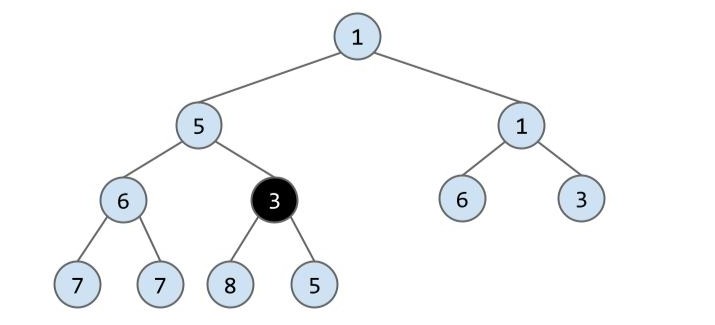
现在仍不满足,所以再重复一次上个操作:
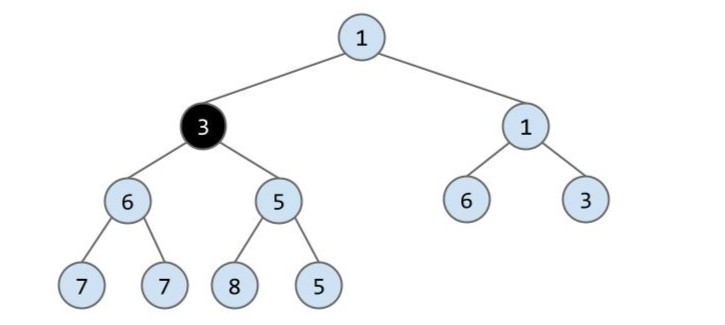
现在终于完成了插入操作。
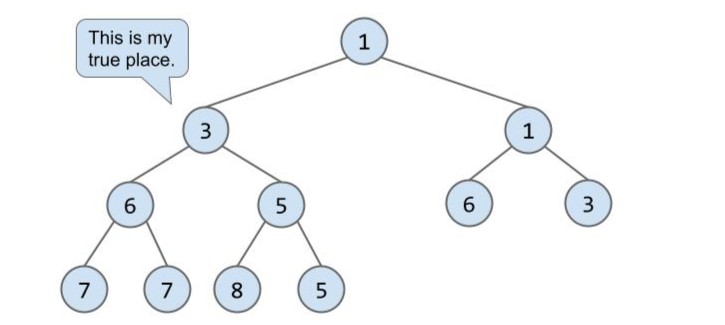
自己试一试:再插入 5 时该如何操作?
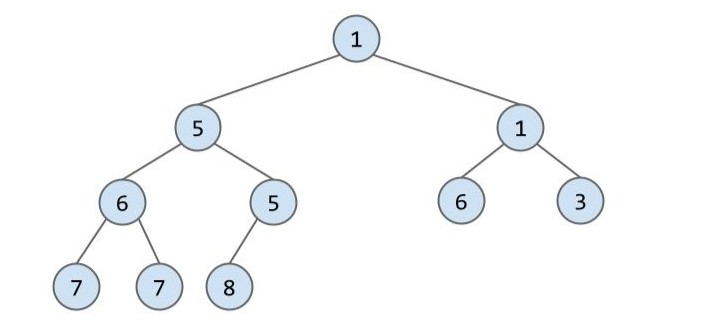
removeSmallest()
如何对下面这个堆 removeSmallest()?
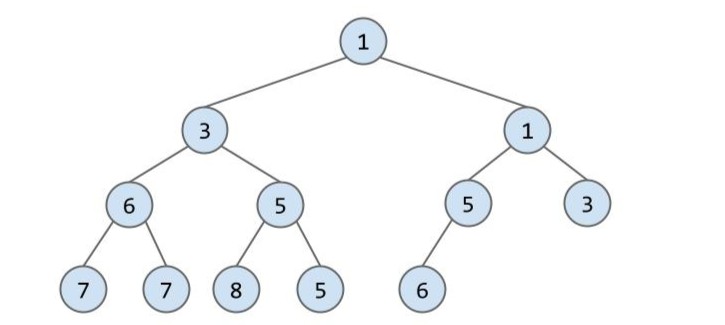
首先我们将已知最小的根节点移除,那剩下的这个空位用谁来填补呢?add() 中运用的思想在这里仍然适用!我们先考虑如何满足完全二叉树的结构?干脆直接将最后一行最右的节点提升上去,就又是完全二叉树了:
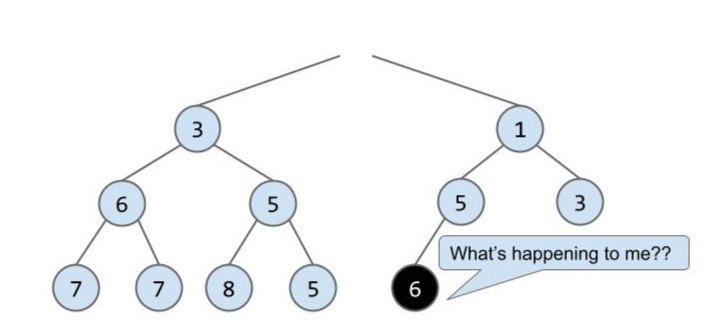
但此时并不满足最小堆的性质,所以我们将 6 与它最小的子节点 1 互换:
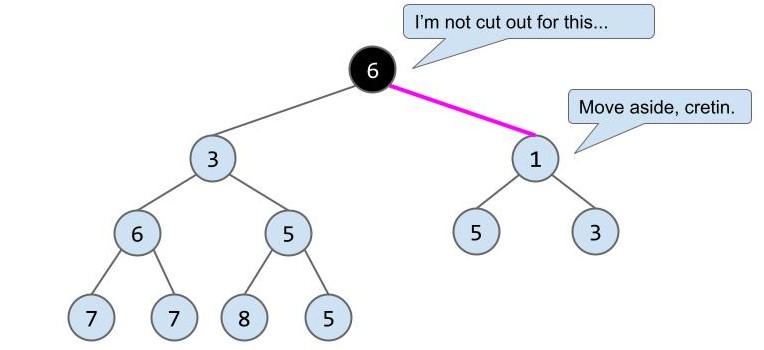
现在仍不满足,所以再重复一次上个操作:
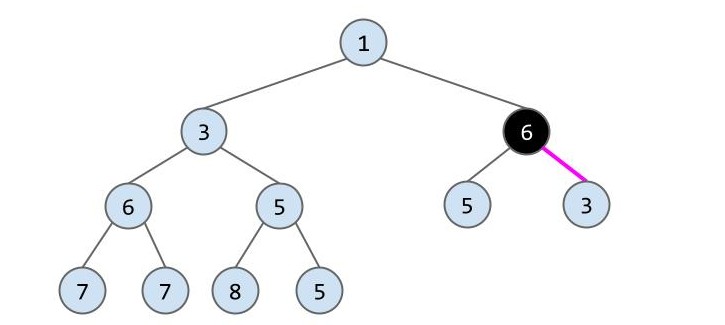
现在终于完成了删除操作。
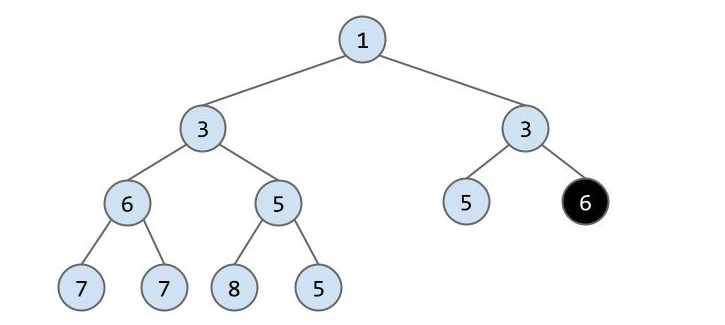
自己试一试:再次删除时该如何操作?
树的表示
很好,我们现在已经明确了堆的一系列操作的逻辑与思路。但要想用 Java 代码编写出来,我们还得先明确一下如何用代码来表示一棵树。
递归表示(1)
每个节点持有对孩子的引用
1a
public class Tree1A<Key> { |
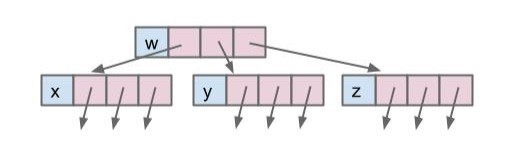
这也是我们在 lab7 中使用的方法。
1b
public class Tree1B<Key> { |
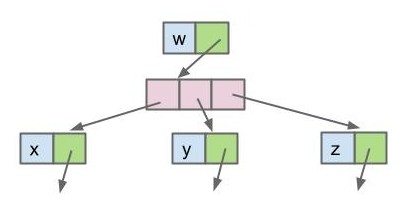
1c
public class Tree1C<Key> { |
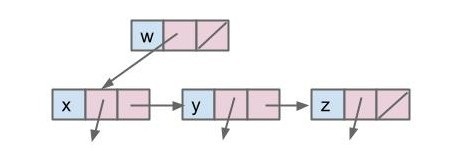
数组表示(2,3)
2
public class Tree2<Key> { |
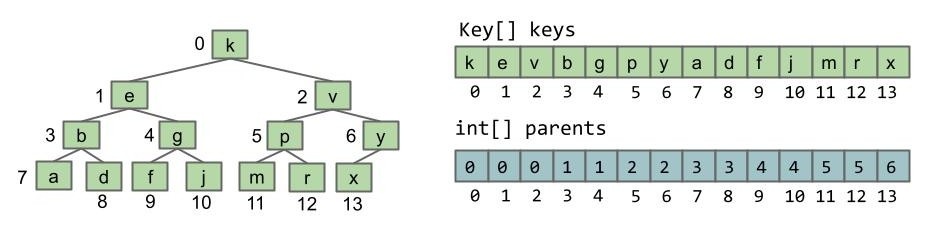
一个数组用于存储键值,一个数组用于存储父节点的编号。
- 与我们在并查集中使用的方法类似,只是并查集中的键值利用数组下标表示。
3
public class Tree3<Key> { |
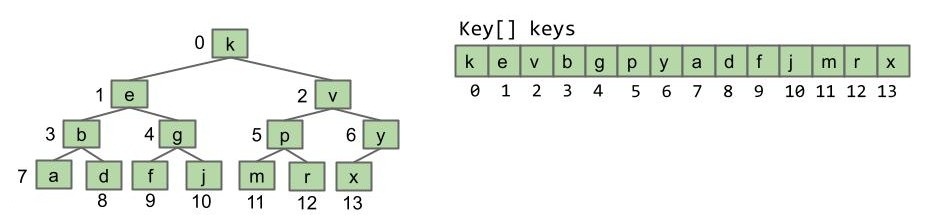
不难发现,对于一棵完全二叉树,parents 数组中的值始终是“0, 0, 1, 1, 2, 2, 3, 3”这些无聊的东西。所以我们干脆只用一个数组存储键值,不再存储数据结构。
- 显然只对完全二叉树有效
而没有了存储父节点的数组,我们如何取到一个节点的父节点呢?
找规律:
- 左子节点编号 = 父节点编号
- 左子节点编号 = 父节点编号
所以可以得到 parent() 方法:
public int parent(int k) { |
当然如果你认为该方法对根节点求父节点的结果是 -1 没有意义,你也可以尝试下面的方法:
3b
将 keys[0] 留空,其余所有元素偏移一格:
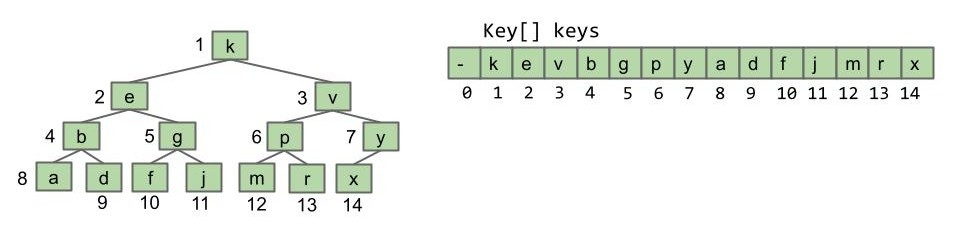
- leftChild(k) = k * 2
- rightChild(k) = k * 2 + 1
- parent(k) = k / 2
这也是普林斯顿算法教材上使用的方法。
PQ 的总结
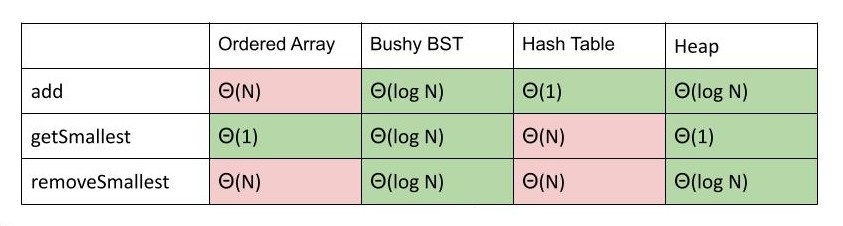
- 堆的 运行时间是摊还分析的结果,因为有时可能需要一些 resize 操作。
- 如果在 BST 中维护一个指向最小值的指针也能实现常数级的
getSmallest()。 - 比起 BST,堆对于重复项的处理更具优势。
- 基于数组实现的堆占用更少的内存(约为方法 1a 的 )。


